Ewolucja konteneryzacji: Dlaczego web deweloperzy nie mogą ignorować Dockera i Kubernetes w 2025 roku
Krajobraz web developmentu uległ zmianie. W poprzednich latach konteneryzacja była często postrzegana jako „problem zespołu DevOps”. Jednak wchodząc w lata 2025 i 2026, granica między pisaniem kodu a zarządzaniem środowiskiem jego wykonania praktycznie się zatarła. Wraz ze wzrostem znaczenia workflow zintegrowanego z AI, architektur micro-frontend oraz platform engineering, Docker i Kubernetes stały się tak samo fundamentalnymi narzędziami w przyborniku web dewelopera, jak Git czy TypeScript.
Nowoczesne aplikacje webowe nie są już tylko zbiorem plików statycznych czy pojedynczym monolitycznym serwerem. To złożone ekosystemy obejmujące lokalne modele LLM (Large Language Models), wektorowe bazy danych i rozproszone funkcje edge. Docker zapewnia spójność niezbędną do spakowania tych różnorodnych komponentów, podczas gdy Kubernetes oferuje orkiestrację, aby zapewnić ich odporność i skalowalność.
Ten przewodnik bada obecny stan konteneryzacji, koncentrując się na najnowszych funkcjach w Docker 4.50+ i Kubernetes v1.33, oraz na tym, jak możesz je wykorzystać do budowania szybszych i bezpieczniejszych aplikacji webowych.
Nowoczesny Docker: Usprawnianie "Inner Loop"
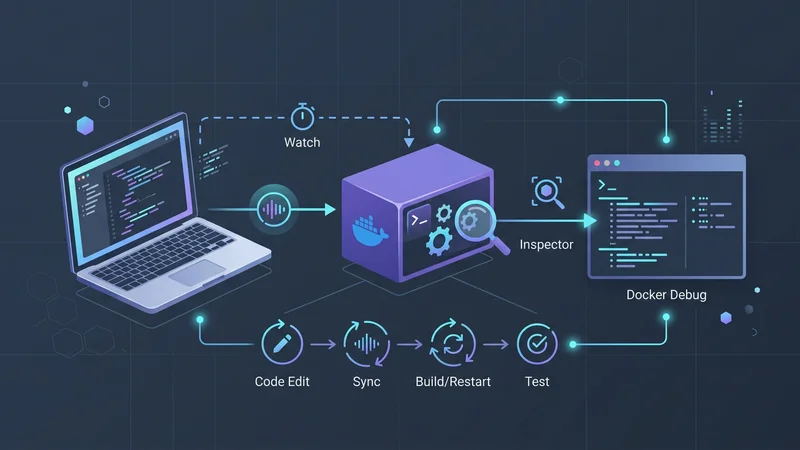
Dla web deweloperów „inner loop” (pętla wewnętrzna) to cykl kodowania, testowania i debugowania. Historycznie Docker dodawał pewne tarcia do tego procesu – czekanie na zakończenie budowania obrazów było częstym zabójcą produktywności. W 2025 roku Docker postawił na programowanie typu „zero-friction”.
Docker Init i Docker Debug
Jednym z najważniejszych dodatków jest docker init. Zamiast ręcznie przeszukiwać StackOverflow w poszukiwaniu idealnego Dockerfile dla swojego backendu w Next.js lub Go, możesz po prostu uruchomić:
docker initTo narzędzie skanuje Twój projekt i generuje zoptymalizowane pliki Dockerfile, .dockerignore oraz compose.yaml, dostosowane do konkretnego frameworka.
Co więcej, Docker Debug (wprowadzony w wersji 4.50+) rozwiązuje dylemat „smukłych obrazów”. Deweloperzy często używają obrazów typu „distroless” lub minimalnych ze względów bezpieczeństwa, ale są one notorycznie trudne do debugowania, ponieważ brakuje im powłoki (shell). Docker Debug dostarcza wbudowany, niezależny od języka zestaw narzędzi, który dołącza się do dowolnego kontenera – nawet tego bez powłoki – pozwalając na inspekcję systemu plików i stanu procesów bez zwiększania rozmiaru obrazu produkcyjnego.
Programowanie w czasie rzeczywistym z Compose Watch
Dni ręcznego wpisywania docker-compose up --build po każdej zmianie w CSS dobiegły końca. Tryb „Watch” w Docker Compose pozwala na synchronizację kodu źródłowego z kontenerem w czasie poniżej sekundy.
# compose.yaml
services:
web:
build: .
ports:
- "3000:3000"
develop:
watch:
- action: sync
path: ./src
target: /app/src
ignore:
- node_modules/
- action: rebuild
path: package.jsonDzięki tej konfiguracji zmiany w katalogu src są błyskawicznie synchronizowane z uruchomionym kontenerem, podczas gdy zmiany w package.json wyzwalają automatyczne przebudowanie obrazu.
Kubernetes dla web deweloperów: Poza szumem medialnym
Jeśli Docker służy do pakowania, to Kubernetes (K8s) służy do przetrwania. Jako web deweloper nie musisz być administratorem klastra, ale musisz rozumieć, jak Kubernetes v1.32 („Penelope”) i v1.33 zarządzają cyklem życia Twojej aplikacji.
Natywne kontenery Sidecar (Native Sidecar Containers)
Głównym problemem w Kubernetes był cykl życia kontenerów sidecar (np. agentów logowania lub proxy autoryzacji). Wcześniej sidecary mogły się wyłączyć, zanim główna aplikacja skończyła przetwarzać ostatnie żądanie, co prowadziło do utraty danych. W v1.33 Natywne Kontenery Sidecar osiągnęły status General Availability. Możesz teraz zdefiniować kontener jako sidecar, upewniając się, że uruchomi się przed Twoją aplikacją i wyłączy się po niej, co zapewnia bezproblemowe działanie service mesh, takich jak Istio czy Linkerd.
Pionowe skalowanie Podów w miejscu (In-Place Pod Vertical Scaling)
Tradycyjnie zmiana limitów CPU lub pamięci Poda wymagała pełnego restartu. Dla aplikacji React/Node.js o dużym natężeniu ruchu oznaczało to krótką przerwę w dostępności lub konieczność stosowania złożonych aktualizacji krokowych (rolling updates). Nowoczesny Kubernetes obsługuje teraz In-Place Pod Vertical Scaling. Możesz aktualizować żądania/limity zasobów w locie, a Kubelet dostosuje zasoby kontenera bez zabijania procesu – idealne rozwiązanie przy nagłych skokach ruchu podczas premiery produktu.
Gateway API: Następca Ingress
Przez lata Ingress API był standardem rutowania ruchu zewnętrznego do usług webowych. Był on jednak ograniczony i często wymagał adnotacji specyficznych dla dostawcy. Kubernetes Gateway API jest teraz standardem. Zapewnia on bardziej ekspresyjny i zorientowany na role sposób zarządzania ruchem, ułatwiając deweloperom definiowanie wdrożeń typu blue-green lub canary bezpośrednio w manifestach.
Architektura aplikacji webowych: Multi-Stage Builds i integracja AI
Budowanie wydajnych obrazów nie jest już opcjonalne. W erze chmurowego przechowywania danych typu „płać za bajt” i efemerycznych środowisk, rozmiar obrazu bezpośrednio wpływa na szybkość i koszt wdrożenia.
Standaryzowane wieloetapowe budowanie (Multi-Stage Builds)
Dla nowoczesnej aplikacji TypeScript/Node.js wieloetapowe budowanie (multi-stage build) jest złotym standardem. Gwarantuje ono, że końcowy obraz produkcyjny zawiera tylko niezbędne artefakty, z wyłączeniem devDependencies i kodu źródłowego.
# Etap 1: Budowanie
FROM node:22-alpine AS builder
WORKDIR /app
COPY package*.json ./
# Użyj npm ci dla deterministycznych buildów w CI/CD
RUN npm ci
COPY . .
RUN npm run build
# Etap 2: Runtime
FROM node:22-alpine AS runner
# Ustawienie środowiska na produkcyjne
ENV NODE_ENV=production
# Uruchamianie jako użytkownik bez uprawnień roota dla bezpieczeństwa
USER node
WORKDIR /app
# Kopiowanie tylko skompilowanych plików i niezbędnych modułów
COPY --from=builder /app/dist ./dist
COPY --from=builder /app/node_modules ./node_modules
COPY --from=builder /app/package.json ./package.json
EXPOSE 3000
CMD ["node", "dist/main.js"]Kontenery AI-Native i DRA
Największym trendem w 2025 roku jest integracja funkcji AI bezpośrednio w aplikacjach webowych. Niezależnie od tego, czy uruchamiasz lokalny LLM dla prywatności danych, czy wektorową bazę danych dla RAG (Retrieval-Augmented Generation), Kubernetes ewoluował, aby wspierać te obciążenia.
Dynamic Resource Allocation (DRA) pozwala Kubernetesowi zarządzać procesorami GPU jako zasobami pierwszej kategorii. Web deweloperzy mogą teraz prosić o ułamkowe części zasobów GPU dla zadań inferencji wewnątrz specyfikacji Podów, podobnie jak proszą o CPU czy RAM.
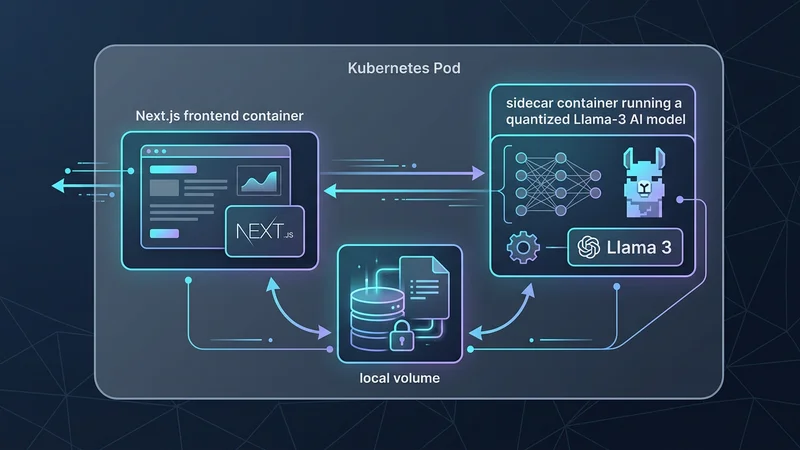 Next.js oraz kontener sidecar z kwantyzowanym modelem AI Llama-3, współdzielących lokalny wolumen dla wag modelu">
Next.js oraz kontener sidecar z kwantyzowanym modelem AI Llama-3, współdzielących lokalny wolumen dla wag modelu">
Bezpieczeństwo i wydajność: Unikanie typowych pułapek
Wraz ze wzrostem złożoności środowisk kontenerowych rośnie również pole do popełniania błędów. Poniżej przedstawiamy najczęstsze pułapki, z którymi mierzą się web deweloperzy, oraz strategie ich unikania.
| Pułapka | Konsekwencja | Strategia zapobiegania |
|---|---|---|
Szerokie COPY . . |
Sekrety (jak .env) lub lokalne logi wyciekają do warstw obrazu. |
Używaj rygorystycznego .dockerignore i skanuj obrazy za pomocą Docker Scout. |
| Brak limitów zasobów | Syndrom „hałaśliwego sąsiada”; jedna usługa zużywa cały RAM węzła. | Zawsze definiuj resources: limits i requests w manifestach K8s. |
Używanie tagów :latest |
Niedeterministyczne wdrożenia; niemożliwość wiarygodnego wycofania zmian. | Używaj wersjonowania semantycznego (np. :v1.2.4) lub skrótów SHA. |
| Uruchamianie jako root | Zwiększone ryzyko luk typu container escape. | Zawsze dołączaj USER node lub konkretny UID w swoim Dockerfile. |
| Ignorowanie sond (Probes) | Ruch wysyłany do kontenerów, które wciąż się uruchamiają lub uległy awarii. | Implementuj livenessProbe i readinessProbe dla każdej usługi. |
Implementacja sond w Node.js
Częstym błędem jest zaniedbywanie monitorowania stanu zdrowia kontenera. Kubernetes musi wiedzieć, kiedy Twoja aplikacja jest gotowa na przyjmowanie ruchu.
// Prosty check gotowości w Express.js
app.get('/healthz/ready', (req, res) => {
// Sprawdź połączenie z DB, cache itp.
const isDbConnected = checkDbStatus();
if (isDbConnected) {
res.status(200).send('Ready');
} else {
res.status(503).send('Service Unavailable');
}
});W Twoim manifeście Kubernetes:
readinessProbe:
httpGet:
path: /healthz/ready
port: 3000
initialDelaySeconds: 5
periodSeconds: 10Krajobraz narzędziowy w 2025 roku
Ekosystem wokół Dockera i Kubernetes dojrzał, oferując narzędzia, które znacząco ułatwiają zarządzanie deweloperom.
- OrbStack: Dla użytkowników macOS, OrbStack w dużej mierze zastąpił Docker Desktop u wielu osób ze względu na znacznie mniejsze obciążenie CPU i RAM oraz błyskawiczny czas uruchamiania.
- Lens / OpenLens: Znany jako „IDE dla Kubernetes”, Lens zapewnia wizualny interfejs do eksploracji klastrów, przeglądania logów, a nawet otwierania powłoki terminala w podach bez konieczności pamiętania złożonych poleceń
kubectl. - KEDA (Kubernetes Event-driven Autoscaling): Podczas gdy K8s skaluje się na podstawie CPU/RAM, KEDA pozwala skalować Pody webowe na podstawie zdarzeń na poziomie aplikacji, takich jak liczba wiadomości w kolejce RabbitMQ czy opóźnienie metryki Prometheus.
- Trivy: To branżowy standard bezpieczeństwa. Zintegruj Trivy ze swoim potokiem CI/CD, aby skanować pliki Dockerfile i YAML Kubernetes pod kątem błędnych konfiguracji i luk w zabezpieczeniach, zanim trafią na produkcję.
Najczęściej zadawane pytania
Czy web deweloperzy naprawdę muszą uczyć się Dockera?
Tak, Docker stał się standardem branżowym zapewniającym spójność środowiska w fazie rozwoju, testów i produkcji. Nauka Dockera pozwala na spakowanie zależności i środowisk wykonawczych, eliminując całkowicie problem „u mnie działa”.
Jaka jest różnica między Dockerem a Kubernetes?
Docker to narzędzie służące do tworzenia, dystrybucji i uruchamiania pojedynczych kontenerów na jednym hoście. Kubernetes to platforma orkiestracji, która zarządza klastrami kontenerów, obsługując skalowanie, równoważenie obciążenia i samonaprawianie na wielu maszynach.
Czy powinienem najpierw nauczyć się Dockera czy Kubernetes?
Zdecydowanie powinieneś najpierw nauczyć się Dockera, ponieważ dostarcza on fundamentalnych klocków (kontenerów), którymi zarządza Kubernetes. Zrozumienie, jak zbudować i uruchomić pojedynczy kontener, jest warunkiem wstępnym do zrozumienia, jak orkiestrować setki z nich w klastrze.
Czy mogę używać Dockera bez Kubernetes w małych projektach?
Oczywiście; w przypadku małych projektów lub prostych aplikacji pobocznych, Docker Compose lub platformy typu „Platform as a Service” (PaaS), takie jak Railway czy Render, są często wystarczające. Kubernetes jest zazwyczaj zarezerwowany dla aplikacji wymagających wysokiej dostępności, złożonego skalowania lub orkiestracji mikrousług.
Jak Kubernetes poprawia skalowalność aplikacji webowych?
Kubernetes poprawia skalowalność dzięki funkcjom takim jak Horizontal Pod Autoscaler (HPA), który automatycznie dodaje więcej instancji aplikacji w zależności od natężenia ruchu. Zarządza również równoważeniem obciążenia i rutowaniem ruchu, zapewniając, że nowe instancje natychmiast zaczynają odbierać żądania bez ręcznej konfiguracji.
Podsumowanie
W latach 2025 i 2026 role „Dewelopera” i „Operatora” nadal łączą się w dyscyplinę Platform Engineering. Dla web deweloperów Docker i Kubernetes nie są już tylko celami wdrożeniowymi; są płótnem, na którym budowane są nowoczesne, odporne i napędzane przez AI aplikacje.
Opanowując „inner loop” za pomocą narzędzi takich jak Docker Compose Watch i docker init oraz rozumiejąc „outer loop” dzięki sidecarom Kubernetes i Gateway API, pozycjonujesz się w czołówce branży. Celem nie jest tylko pisanie kodu, który działa – celem jest pisanie kodu, który się skaluje, przetrwa i odniesie sukces w świecie cloud-native. Zacznij od małych kroków, skonteneryzuj swój obecny projekt i stopniowo odkrywaj moc orkiestracji, którą daje Kubernetes. Przyszłość sieci jest skonteneryzowana.