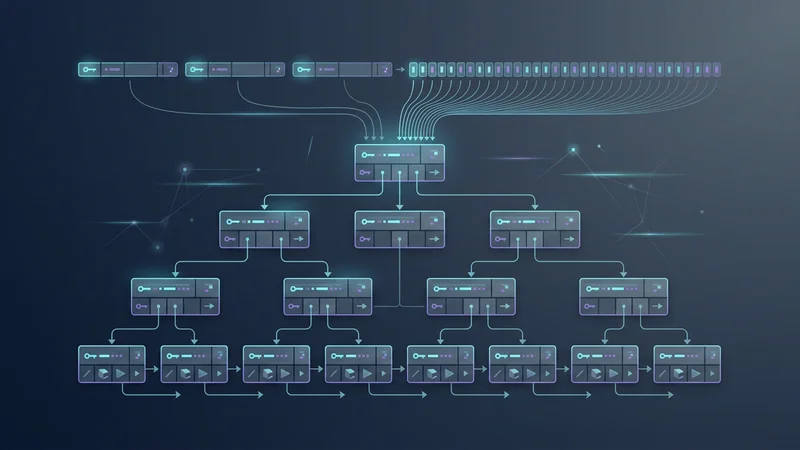
Wprowadzenie: Ewolucja Multi-Tenancy
W szybko zmieniającym się krajobrazie Software-as-a-Service (SaaS), baza danych nie jest już tylko silnikiem do przechowywania danych — to kręgosłup architektoniczny, który decyduje o skalowalności, bezpieczeństwie i marżach zysku Twojej aplikacji. Wchodząc w rok 2025 i 2026, uniwersalne podejście "one-size-fits-all" do projektowania baz danych zostało zastąpione przez zaawansowane wzorce, które równoważą izolację najemców (tenants) z wydajnością operacyjną.
Nowoczesne zespoły inżynierskie SaaS odchodzą od monolitycznych baz danych na rzecz bardziej granularnych architektur "zorientowanych na najemców" (tenant-aware). Wraz z wydaniem PostgreSQL 18 i dojrzewaniem technologii serverless database, deweloperzy mają teraz dostęp do narzędzi, które wcześniej były zarezerwowane dla korporacji o skali FAANG. Niezależnie od tego, czy budujesz niszowe narzędzie B2B, czy globalną platformę korporacyjną, wybór odpowiedniego wzorca projektowania bazy danych jest najważniejszą decyzją techniczną, jaką podejmiesz.
Wzorce architektury baz danych Multi-Tenant
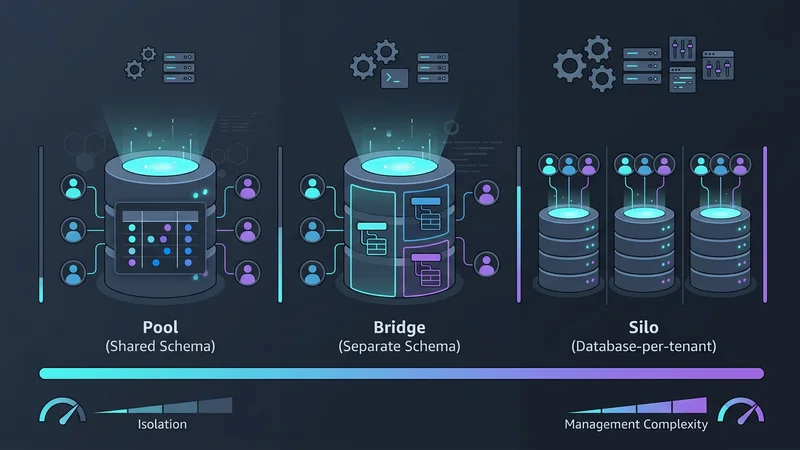
Wybór modelu multi-tenancy wiąże się z kompromisem między trzema czynnikami: Izolacją, Skalowalnością i Kosztem. W 2026 roku kategoryzujemy je na trzy główne wzorce: Pool, Bridge i Silo.
Wzorzec 1: Współdzielona baza danych, współdzielony schemat (Model Pool)
Model "Pool" jest najczęstszą architekturą dla aplikacji SaaS o dużym wolumenie i niskich kosztach. W tym wzorcu wszyscy najemcy współdzielą tę samą bazę danych i te same tabele. Dane są logicznie separowane za pomocą kolumny tenant_id w każdej tabeli.
Zalety:
- Efektywność kosztowa: Płacisz tylko za jedną instancję bazy danych.
- Prosta agregacja: Przeprowadzanie analityki dla wszystkich klientów jest proste.
- Utrzymanie: Jeden schemat do migracji, jeden zestaw indeksów do zarządzania.
Wady:
- Efekt "głośnego sąsiada" (Noisy Neighbor): Pojedynczy, intensywny użytkownik może obniżyć wydajność dla wszystkich pozostałych.
- Ryzyko bezpieczeństwa: Błąd w klauzuli
WHEREw aplikacji może doprowadzić do wycieku danych.
Wzorzec 2: Współdzielona baza danych, oddzielne schematy (Model Bridge)
Często stosowany w HealthTech lub FinTech, model "Bridge" stanowi złoty środek. Każdy najemca otrzymuje własny schemat (np. tenant_a.orders, tenant_b.orders) w ramach jednej fizycznej instancji bazy danych.
Model ten jest preferowany w 2025 roku w środowiskach o wysokich wymaganiach regulacyjnych, takich jak aplikacje zgodne z HIPAA. Zapewnia logiczną separację, utrudniając wyciek danych między najemcami, jednocześnie pozwalając zespołowi infrastruktury na zarządzanie pojedynczym klastrem bazy danych.
Wzorzec 3: Baza danych na najemcę (Model Silo)
Historycznie, przydzielanie każdemu klientowi własnej bazy danych było uważane za operacyjny koszmar. Jednak rozwój dostawców serverless, takich jak Neon i AWS Aurora Serverless v2, zrewolucjonizował to podejście. Platformy te pozwalają na funkcję "scale-to-zero", co oznacza, że baza danych najemcy nie generuje kosztów, gdy nie jest używana.
Dlaczego wygrywa w 2026 roku:
- Zero wycieków: Fizyczna separacja gwarantuje, że jeden najemca nie ma dostępu do danych innego.
- Personalizacja: Możesz uruchamiać różne migracje lub wersje dla konkretnych klientów korporacyjnych.
- Branching: Korzystając z branchingu "copy-on-write", możesz błyskawicznie wdrażać nowych najemców poprzez klonowanie szablonowej bazy danych.
Nowoczesne innowacje i najlepsze praktyki (2025–2026)
Wydanie PostgreSQL 18 fundamentalnie zmieniło sposób implementacji tych wzorców. Wyróżniają się dwie funkcje: natywne asynchroniczne I/O (AIO) oraz natywne wsparcie dla UUIDv7.
Przejście na UUIDv7
Przez lata deweloperzy debatowali między sekwencyjnymi liczbami całkowitymi (szybkie, ale niebezpieczne) a losowymi UUIDv4 (bezpieczne, ale wolne dla indeksów). UUIDv7 jest standardem na rok 2026, ponieważ jest uporządkowany czasowo. Zapobiega to fragmentacji indeksu B-tree, typowej dla losowych UUID, utrzymując szybkość operacji insert nawet wtedy, gdy Twój SaaS rozrośnie się do miliardów wierszy.
Izolacja wektorowa w AI-Native SaaS
Wraz ze wzrostem popularności Retrieval-Augmented Generation (RAG), bazy danych SaaS przechowują teraz embeddingi wektorowe. "Wzorzec izolacji wektorowej" (Vector Isolation Pattern) polega na wykorzystaniu Row-Level Security (RLS) na kolumnach wektorowych, aby zapewnić, że agent AI pobiera tylko kontekst istotny dla konkretnego najemcy, zapobiegając "halucynacjom AI" obejmującym dane innych klientów.
Izolacja danych i strategie identyfikacji najemców
Izolacja to "święty Graal" SaaS. W 2026 roku branża ustandaryzowała dwie główne metody zapewniania, że żaden klient nie zobaczy danych innego.
Row-Level Security (RLS): Złoty Standard
Jeśli używasz modelu "Pool", Row-Level Security w PostgreSQL jest obowiązkowe. Zamiast ręcznie dopisywać tenant_id do każdego zapytania, definiujesz politykę na poziomie bazy danych.
-- Włącz RLS na tabeli
ALTER TABLE orders ENABLE ROW LEVEL SECURITY;
-- Utwórz politykę ograniczającą dostęp na podstawie zmiennej sesyjnej
CREATE POLICY tenant_isolation_policy ON orders
USING (tenant_id = current_setting('app.current_tenant')::uuid);Identyfikacja najemcy poprzez Middleware
Aby RLS działało, Twoja aplikacja musi "powiedzieć" bazie danych, który najemca jest aktualnie aktywny. W nowoczesnym stosie TypeScript używającym Drizzle ORM lub Prisma, jest to obsługiwane w middleware żądania.
// middleware/tenant-resolver.ts
import { NextFunction, Request, Response } from 'express';
import { db } from '../db';
export async function tenantMiddleware(req: Request, res: Response, next: NextFunction) {
const tenantId = req.auth.claims.tenant_id; // Wyodrębnione z JWT
if (!tenantId) {
return res.status(401).send('Unauthorized');
}
// Użyj transakcji, aby ustawić zmienną lokalną dla tego połączenia
await db.transaction(async (tx) => {
await tx.execute(sql`SET LOCAL app.current_tenant = ${tenantId}`);
// Przechowaj obiekt transakcji w żądaniu do użytku w kontrolerach
req.tenantDb = tx;
next();
});
}Ostrzeżenie: Zawsze używaj SET LOCAL wewnątrz transakcji. Jeśli użyjesz SET globalnie na połączeniu z puli (pooled connection), tenant_id może "przykleić się" do połączenia i wyciec do następnego użytkownika — zjawisko znane jako Pool Contamination.
Wyzwania skalowania i problem "Głośnego Sąsiada"
W miarę skalowania SaaS, ostatecznie napotkasz "Głośnego Sąsiada" (Noisy Neighbor) — pojedynczego najemcę, którego zużycie zasobów gwałtownie rośnie, pozbawiając innych najemców zasobów (CPU, pamięć, I/O).
Architektura komórkowa (Cell-Based Architecture)
Aby temu zapobiec, aplikacje SaaS o ogromnej skali (jak Slack czy Salesforce) stosują architekturę komórkową. Zamiast jednej gigantycznej bazy danych dla 1 000 000 najemców, tworzysz "komórki". Każda komórka jest autonomiczną jednostką (np. klaster bazy danych + zasoby obliczeniowe), która obsługuje 50 000 najemców.
- Promień rażenia (Blast Radius): Jeśli komórka A ulegnie awarii, dotyczy to tylko 5% Twoich klientów.
- Globalna ekspansja: Możesz umieścić komórkę B w UE, a komórkę C w USA, aby spełnić wymogi dotyczące rezydencji danych.
Distributed SQL dla globalnych SaaS
Dla aplikacji wymagających jednej logicznej, globalnej bazy danych, preferowanym wyborem są silniki Distributed SQL, takie jak CockroachDB v25.4. Pozwalają one "przypiąć" konkretne wiersze do regionów geograficznych za pomocą strategii regional_by_row, zapewniając niskie opóźnienia dla użytkowników przy zachowaniu globalnej spójności.
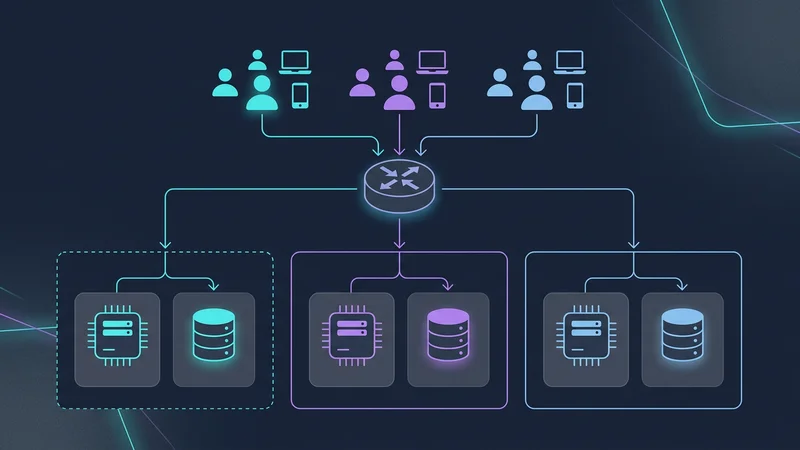 Architecture), gdzie różne grupy najemców są kierowane do oddzielnych 'komórek' bazy danych, aby zapobiegać problemom z głośnymi sąsiadami i ograniczać promień rażenia">
Architecture), gdzie różne grupy najemców są kierowane do oddzielnych 'komórek' bazy danych, aby zapobiegać problemom z głośnymi sąsiadami i ograniczać promień rażenia">
Najlepsze praktyki migracji schematu i utrzymania
Zarządzanie migracjami dla 10 000 oddzielnych schematów najemców jest niemożliwym zadaniem manualnym. Automatyzacja poprzez Infrastructure-as-Code (IaC) to jedyna droga naprzód.
Automatyzacja migracji multi-tenant
Nowoczesne narzędzia, takie jak drizzle-multitenant lub niestandardowe providery Terraform, pozwalają traktować schematy baz danych jak kod. Gdy aktualizujesz "Schemat Szablonowy", potok CI/CD przechodzi przez wszystkie bazy danych najemców i aplikuje zmiany.
# Przykład: Uruchamianie migracji we wszystkich schematach najemców
npx drizzle-kit push:pg --config=./drizzle.config.ts --all-tenantsKluczowe pułapki, których należy unikać:
- Losowe UUID: Jak wspomniano, unikaj UUIDv4 dla kluczy głównych. Używaj UUIDv7.
- Wyczerpanie połączeń: Skalowanie do 5 000 najemców z oddzielnymi połączeniami spowoduje awarię bazy danych. Użyj poolera połączeń zorientowanego na najemców, takiego jak Supabase Supavisor lub PgBouncer.
- Brak indeksów w kolumnach najemców: W modelu współdzielonego schematu każdy pojedynczy indeks musi zawierać
tenant_idjako pierwszą lub drugą kolumnę, aby optymalizator zapytań mógł wydajnie filtrować dane.
Często zadawane pytania
Jaka jest różnica między modelami bazy danych silo, bridge i pool?
Model Silo zapewnia każdemu najemcy dedykowaną instancję bazy danych, oferując maksymalną izolację, ale wyższe koszty zarządzania. Model Bridge wykorzystuje współdzieloną instancję bazy danych z oddzielnymi schematami dla każdego najemcy, równoważąc izolację i koszty. Model Pool wykorzystuje współdzielony schemat, w którym dane wszystkich najemców znajdują się w tych samych tabelach, oddzielone identyfikatorem najemcy, co oferuje najwyższą efektywność kosztową, ale największe ryzyko.
Jak zapewnić izolację danych we współdzielonej bazie danych multi-tenant?
Izolacja danych jest zapewniana głównie poprzez Row-Level Security (RLS) na poziomie bazy danych, co ogranicza dostęp na podstawie kontekstu sesji użytkownika. Dodatkowo, middleware na poziomie aplikacji musi rygorystycznie wymuszać identyfikację najemcy poprzez wstrzykiwanie poprawnego tenant_id do każdego zapytania lub zmiennej sesyjnej. Używanie uporządkowanych czasowo identyfikatorów, takich jak UUIDv7, również pomaga zachować wydajność i porządek w ramach współdzielonych indeksów.
Która architektura bazy danych jest najlepsza dla skalującej się aplikacji SaaS?
Dla SaaS na wczesnym etapie model Pool z RLS jest zazwyczaj najlepszy ze względu na niskie koszty i prostotę. W miarę skalowania do klientów korporacyjnych preferowana jest architektura hybrydowa lub komórkowa, w której większość użytkowników pozostaje we współdzielonej puli, podczas gdy wysokowartościowi klienci korporacyjni są migrowani do dedykowanych silosów dla lepszej wydajności i zgodności.
Jak radzić sobie z migracjami schematów dla tysięcy najemców?
Migracje schematów powinny być obsługiwane przy użyciu Infrastructure-as-Code (IaC) i zautomatyzowanych narzędzi do migracji, które mogą wykonywać zmiany równolegle we wszystkich schematach. Narzędzia takie jak Drizzle ORM lub wyspecjalizowane skrypty CI/CD są używane do zapewnienia, że migracje są idempotentne, a niepowodzenie migracji jednego najemcy nie zatrzymuje całego procesu wdrażania.
Czy multi-tenancy może wpływać na wydajność bazy danych i opóźnienia?
Tak, multi-tenancy może prowadzić do problemu głośnego sąsiada, gdzie intensywne zużycie zasobów przez jednego najemcę spowalnia zapytania innych. Co więcej, bez odpowiedniego indeksowania kolumny tenant_id i korzystania z poolerów połączeń, narzut związany z zarządzaniem tysiącami kontekstów najemców może znacznie zwiększyć opóźnienia i ryzyko wyczerpania połączeń.
Podsumowanie
Projektowanie baz danych dla SaaS w latach 2025–2026 to już nie tylko wybór między SQL a NoSQL. Chodzi o wybór strategii, która jest zgodna z Twoimi celami biznesowymi.
Jeśli budujesz aplikację konsumencką o dużym wolumenie, model Współdzielonego Schematu (Pool) z PostgreSQL 18 i RLS oferuje najlepszą wydajność i koszt. Jeśli celujesz w rynek korporacyjny, model Serverless Silo zapewnia izolację i zgodność, których wymagają Twoi klienci, bez historycznego narzutu związanego z zarządzaniem tysiącami serwerów.
Poprzez standaryzację na UUIDv7, wdrażanie architektur komórkowych dla skali i wykorzystanie zautomatyzowanych zestawów narzędzi do migracji, możesz zbudować backend SaaS, który będzie nie tylko solidny dzisiaj, ale gotowy na wymagania następnej dekady.