Introduzione: L'Evoluzione del Multi-Tenant
Nel panorama in rapida evoluzione del Software-as-a-Service (SaaS), il database non è più solo un motore di archiviazione: è la spina dorsale architetturale che determina la scalabilità, la sicurezza e i margini di profitto della tua applicazione. Mentre avanziamo nel 2025 e verso il 2026, l'approccio "taglia unica" alla progettazione dei database è stato sostituito da pattern sofisticati che bilanciano l'isolamento dei tenant con l'efficienza operativa.
I moderni team di ingegneria SaaS si stanno allontanando dai database monolitici verso architetture più granulari e "tenant-aware". Con il rilascio di PostgreSQL 18 e la maturazione delle tecnologie di database serverless, gli sviluppatori dispongono ora di strumenti che in precedenza erano riservati alle imprese di scala FAANG. Che tu stia costruendo uno strumento B2B di nicchia o una piattaforma aziendale globale, scegliere il giusto pattern di progettazione del database è la decisione tecnica più critica che prenderai.
Pattern di Architettura Database Multi-Tenant
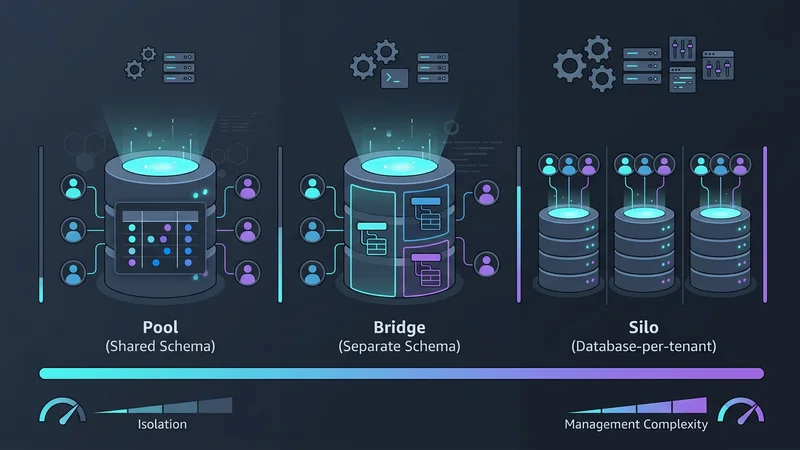
La scelta di un modello di multi-tenancy comporta un compromesso tra tre fattori: Isolamento, Scalabilità e Costo. Nel 2026, classifichiamo questi in tre pattern primari: il Pool, il Bridge e il Silo.
Pattern 1: Database Condiviso, Schema Condiviso (Il Modello Pool)
Il modello "Pool" è l'architettura più comune per le applicazioni SaaS ad alto volume e basso costo. In questo pattern, tutti i tenant condividono lo stesso database e le stesse tabelle. I dati sono separati logicamente da una colonna tenant_id in ogni tabella.
Pro:
- Efficienza dei costi: Paghi solo per un'istanza di database.
- Aggregazione semplice: Eseguire analisi su tutti i clienti è immediato.
- Manutenzione: Un solo schema da migrare, un solo set di indici da gestire.
Contro:
- Effetto Noisy Neighbor: Un singolo utente pesante può degradare le prestazioni per tutti gli altri.
- Rischio di Sicurezza: Un bug nella clausola
WHEREdella tua applicazione potrebbe causare una fuga di dati.
Pattern 2: Database Condiviso, Schemi Separati (Il Modello Bridge)
Spesso utilizzato in ambito HealthTech o FinTech, il modello "Bridge" rappresenta una via di mezzo. Ogni tenant ottiene il proprio schema (ad es. tenant_a.orders, tenant_b.orders) all'interno di una singola istanza fisica di database.
Questo modello è preferito nel 2025 per ambienti con rigidi requisiti di conformità, come le app conformi a HIPAA. Fornisce una separazione logica, rendendo più difficile la fuga di dati tra i tenant, pur consentendo al team infrastrutturale di gestire un singolo cluster di database.
Pattern 3: Database per Tenant (Il Modello Silo)
Storicamente, assegnare a ogni cliente il proprio database era considerato un incubo operativo. Tuttavia, l'ascesa di provider serverless come Neon e AWS Aurora Serverless v2 ha rivoluzionato questo approccio. Queste piattaforme consentono funzionalità di "scale-to-zero", il che significa che il database di un tenant non costa nulla quando non viene utilizzato.
Perché sta vincendo nel 2026:
- Zero Leakage: La separazione fisica garantisce che un tenant non possa accedere ai dati di un altro.
- Personalizzazione: È possibile eseguire migrazioni o versioni diverse per specifici clienti enterprise.
- Branching: Utilizzando il branching "copy-on-write", è possibile integrare nuovi tenant istantaneamente clonando un database modello.
Innovazioni Moderne e Best Practice (2025–2026)
Il rilascio di PostgreSQL 18 ha cambiato radicalmente il modo in cui implementiamo questi pattern. Due caratteristiche spiccano: l'I/O Asincrono Nativo (AIO) e il supporto nativo per UUIDv7.
Il Passaggio a UUIDv7
Per anni, gli sviluppatori hanno dibattuto tra interi sequenziali (veloci ma non sicuri) e UUIDv4 casuali (sicuri ma lenti per gli indici). UUIDv7 è lo standard del 2026 perché è ordinato temporalmente. Ciò previene la frammentazione degli indici B-tree comune con gli UUID casuali, mantenendo veloci i tuoi inserimenti anche quando il tuo SaaS cresce fino a miliardi di righe.
Isolamento Vettoriale in SaaS AI-Native
Con l'ascesa della Retrieval-Augmented Generation (RAG), i database SaaS stanno ora memorizzando embedding vettoriali. Il "Vector Isolation Pattern" prevede l'uso della Row-Level Security (RLS) sulle colonne vettoriali per garantire che un agente AI recuperi solo il contesto pertinente allo specifico tenant, prevenendo "allucinazioni AI" che coinvolgono i dati di altri clienti.
Strategie di Isolamento dei Dati e Risoluzione dei Tenant
L'isolamento è il "sacro graal" del SaaS. Nel 2026, l'industria si è standardizzata su due metodi primari per garantire che nessun cliente veda mai i dati di un altro.
Row-Level Security (RLS): Lo Standard d'Oro
Se stai usando il modello "Pool", la Row-Level Security di PostgreSQL è obbligatoria. Invece di aggiungere manualmente tenant_id a ogni query, definisci una policy a livello di database.
-- Enable RLS on the table
ALTER TABLE orders ENABLE ROW LEVEL SECURITY;
-- Create a policy that restricts access based on a session variable
CREATE POLICY tenant_isolation_policy ON orders
USING (tenant_id = current_setting('app.current_tenant')::uuid);Risoluzione dei Tenant tramite Middleware
Per far funzionare l'RLS, la tua applicazione deve "comunicare" al database quale tenant è attualmente attivo. In uno stack TypeScript moderno che utilizza Drizzle ORM o Prisma, questo viene gestito nel middleware della richiesta.
// middleware/tenant-resolver.ts
import { NextFunction, Request, Response } from 'express';
import { db } from '../db';
export async function tenantMiddleware(req: Request, res: Response, next: NextFunction) {
const tenantId = req.auth.claims.tenant_id; // Extracted from JWT
if (!tenantId) {
return res.status(401).send('Unauthorized');
}
// Use a transaction to set the local variable for this connection
await db.transaction(async (tx) => {
await tx.execute(sql`SET LOCAL app.current_tenant = ${tenantId}`);
// Store the transaction object in the request for use in controllers
req.tenantDb = tx;
next();
});
}Attenzione: Usa sempre SET LOCAL all'interno di una transazione. Se usi SET globalmente su una connessione in pool, il tenant_id potrebbe "rimanere attaccato" alla connessione e trapelare all'utente successivo, un fenomeno noto come Pool Contamination.
Sfide di Scalabilità e il Problema del Noisy Neighbor
Man mano che il tuo SaaS scala, incontrerai inevitabilmente un "Noisy Neighbor": un singolo tenant il cui utilizzo aumenta così tanto da privare gli altri tenant delle risorse (CPU, Memoria, I/O).
Architettura a Celle (Cell-Based Architecture)
Per mitigare questo problema, le applicazioni SaaS su scala ultra-elevata (come Slack e Salesforce) utilizzano l'Architettura a Celle. Invece di un unico database gigante per 1.000.000 di tenant, si creano delle "celle". Ogni cella è un'unità autonoma (ad es. un cluster di database + calcolo) che ospita 50.000 tenant.
- Raggio d'impatto: Se la Cella A va giù, solo il 5% dei tuoi clienti ne risente.
- Espansione Globale: Puoi posizionare la Cella B nell'UE e la Cella C negli Stati Uniti per soddisfare le leggi sulla residenza dei dati.
SQL Distribuito per SaaS Globali
Per le applicazioni che richiedono un unico database logico globale, i motori SQL distribuiti come CockroachDB v25.4 sono la scelta preferita. Consentono di "fissare" righe specifiche a regioni geografiche utilizzando una strategia regional_by_row, garantendo bassa latenza per gli utenti e mantenendo la coerenza globale.
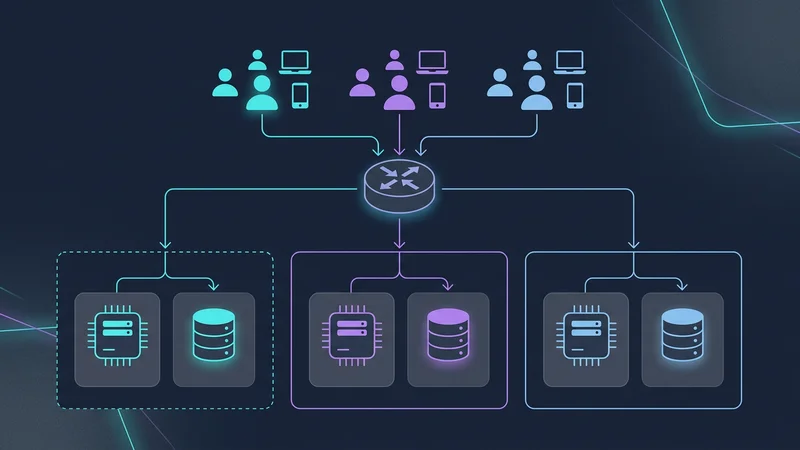 Architecture dove diversi gruppi di tenant sono indirizzati a 'celle' di database separate per prevenire problemi di noisy neighbor e limitare il raggio d'impatto">
Architecture dove diversi gruppi di tenant sono indirizzati a 'celle' di database separate per prevenire problemi di noisy neighbor e limitare il raggio d'impatto">
Migrazione degli Schemi e Best Practice di Manutenzione
Gestire le migrazioni per 10.000 schemi di tenant separati è un compito manuale impossibile. L'automazione tramite Infrastructure-as-Code (IaC) è l'unica via percorribile.
Automazione delle Migrazioni Multi-Tenant
Toolkit moderni come drizzle-multitenant o provider Terraform personalizzati ti consentono di trattare i tuoi schemi di database come codice. Quando aggiorni il tuo "Schema Modello", la pipeline CI/CD itera attraverso tutti i database dei tenant e applica le modifiche.
# Esempio: Esecuzione delle migrazioni su tutti gli schemi dei tenant
npx drizzle-kit push:pg --config=./drizzle.config.ts --all-tenantsErrori Chiave da Evitare:
- UUID Casuali: Come menzionato, evita UUIDv4 per le chiavi primarie. Usa UUIDv7.
- Esaurimento delle Connessioni: Scalare a 5.000 tenant con connessioni separate farà crashare il tuo DB. Usa un connection pooler consapevole dei tenant come Supabase Supavisor o PgBouncer.
- Indici Mancanti sulle Colonne Tenant: In uno schema condiviso, ogni singolo indice deve includere
tenant_idcome prima o seconda colonna per garantire che l'ottimizzatore della query possa filtrare i dati in modo efficiente.
Domande Frequenti
Qual è la differenza tra i modelli di database silo, bridge e pool?
Il modello Silo fornisce a ogni tenant un'istanza di database dedicata, offrendo il massimo isolamento ma un maggiore sovraccarico di gestione. Il modello Bridge utilizza un'istanza di database condivisa con schemi separati per ogni tenant, bilanciando isolamento e costi. Il modello Pool utilizza uno schema condiviso in cui tutti i dati dei tenant risiedono nelle stesse tabelle, separati da un ID tenant, offrendo la massima efficienza dei costi ma il rischio maggiore.
Come si garantisce l'isolamento dei dati in un database multi-tenant condiviso?
L'isolamento dei dati è garantito principalmente attraverso la Row-Level Security (RLS) a livello di database, che limita l'accesso in base al contesto della sessione dell'utente. Inoltre, il middleware a livello di applicazione deve imporre rigorosamente la risoluzione del tenant iniettando il corretto tenant_id in ogni query o variabile di sessione. L'uso di identificatori ordinati nel tempo come UUIDv7 aiuta anche a mantenere le prestazioni e l'organizzazione all'interno degli indici condivisi.
Quale architettura di database è la migliore per un'applicazione SaaS in crescita?
Per un SaaS in fase iniziale, il modello Pool con RLS è solitamente il migliore grazie al basso costo e alla semplicità. Man mano che si scala verso clienti enterprise, è preferibile un'architettura Ibrida o a Celle, dove la maggior parte degli utenti rimane in un pool condiviso mentre i clienti enterprise di alto valore vengono migrati in silo dedicati per migliori prestazioni e conformità.
Come si gestiscono le migrazioni degli schemi per migliaia di tenant?
Le migrazioni degli schemi dovrebbero essere gestite utilizzando Infrastructure-as-Code (IaC) e runner di migrazione automatizzati in grado di eseguire modifiche in parallelo su tutti gli schemi. Strumenti come Drizzle ORM o script CI/CD specializzati vengono utilizzati per garantire che le migrazioni siano idempotenti e che i fallimenti nella migrazione di un tenant non interrompano l'intero processo di distribuzione.
La multi-tenancy può influenzare le prestazioni e la latenza del database?
Sì, la multi-tenancy può portare al problema del Noisy Neighbor, dove l'uso intensivo di risorse da parte di un tenant rallenta le query per gli altri. Inoltre, senza una corretta indicizzazione su tenant_id e l'uso di connection pooler, il sovraccarico della gestione di migliaia di contesti tenant può aumentare significativamente la latenza e rischiare l'esaurimento delle connessioni.
Conclusione
La progettazione dei database per il SaaS nel 2025–2026 non riguarda più solo la scelta tra SQL e NoSQL. Si tratta di scegliere una strategia che sia in linea con i tuoi obiettivi di business.
Se stai costruendo un'app consumer ad alto volume, il modello a Schema Condiviso (Pool) con PostgreSQL 18 e RLS offre le migliori prestazioni e costi. Se ti rivolgi al mercato enterprise, il modello Silo Serverless fornisce l'isolamento e la conformità richiesti dai tuoi clienti senza il sovraccarico storico della gestione di migliaia di server.
Standardizzando su UUIDv7, implementando Architetture a Celle per la scalabilità e sfruttando toolkit di migrazione automatizzati, puoi costruire un backend SaaS che non sia solo robusto oggi, ma pronto per le sfide del prossimo decennio.