Einleitung: Die Multi-Tenant-Evolution
In der sich schnell entwickelnden Landschaft von Software-as-a-Service (SaaS) ist die Datenbank nicht mehr nur eine Storage Engine – sie ist das architektonische Rückgrat, das über die Skalierbarkeit, Sicherheit und die Gewinnmargen Ihrer Anwendung entscheidet. Auf dem Weg durch das Jahr 2025 und in das Jahr 2026 wurde der „Einheitsansatz“ für das Datenbankdesign durch anspruchsvolle Patterns ersetzt, die Tenant-Isolierung mit betrieblicher Effizienz ausbalancieren.
Moderne SaaS-Engineering-Teams bewegen sich weg von monolithischen Datenbanken hin zu granulareren, „Tenant-aware“ Architekturen. Mit dem Release von PostgreSQL 18 und der Reifung von Serverless-Datenbanktechnologien verfügen Entwickler nun über Werkzeuge, die früher nur Unternehmen auf FAANG-Niveau vorbehalten waren. Egal, ob Sie ein spezialisiertes B2B-Tool oder eine globale Enterprise-Plattform bauen, die Wahl des richtigen Datenbank-Design-Patterns ist die kritischste technische Entscheidung, die Sie treffen werden.
Architektur-Patterns für Multi-Tenant-Datenbanken
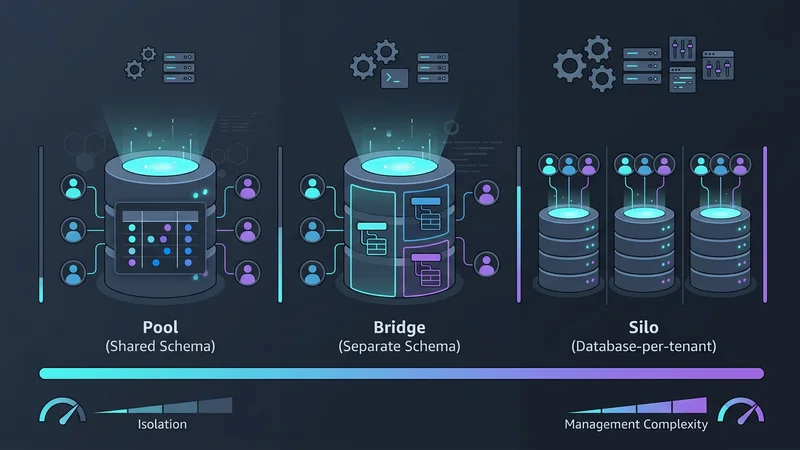
Die Wahl eines Multi-Tenancy-Modells erfordert einen Kompromiss zwischen drei Faktoren: Isolierung, Skalierbarkeit und Kosten. Im Jahr 2026 kategorisieren wir diese in drei primäre Patterns: den Pool, die Bridge und das Silo.
Pattern 1: Gemeinsame Datenbank, gemeinsames Schema (Das Pool-Modell)
Das „Pool“-Modell ist die am weitesten verbreitete Architektur für hochvolumige, kostengünstige SaaS-Anwendungen. In diesem Pattern teilen sich alle Tenants dieselbe Datenbank und dieselben Tabellen. Die Daten werden logisch durch eine tenant_id-Spalte in jeder Tabelle getrennt.
Vorteile:
- Kosteneffizienz: Sie zahlen nur für eine Datenbankinstanz.
- Einfache Aggregation: Analysen über alle Kunden hinweg sind unkompliziert.
- Wartung: Ein Schema zum Migrieren, ein Satz von Indizes zum Verwalten.
Nachteile:
- Noisy-Neighbor-Effekt: Ein einzelner intensiver Nutzer kann die Performance für alle anderen beeinträchtigen.
- Sicherheitsrisiko: Ein Bug in der
WHERE-Klausel Ihrer Anwendung könnte zu Datenlecks führen.
Pattern 2: Gemeinsame Datenbank, separate Schemas (Das Bridge-Modell)
Oft in den Bereichen HealthTech oder FinTech eingesetzt, bietet das „Bridge“-Modell einen Mittelweg. Jeder Tenant erhält sein eigenes Schema (z. B. tenant_a.orders, tenant_b.orders) innerhalb einer einzigen physischen Datenbankinstanz.
Dieses Modell wird 2025 für Umgebungen mit hohen Compliance-Anforderungen wie HIPAA-konforme Apps bevorzugt. Es bietet eine logische Trennung, die den Datenaustausch zwischen Tenants erschwert, während das Infrastruktur-Team weiterhin nur einen einzigen Datenbank-Cluster verwalten muss.
Pattern 3: Datenbank-pro-Tenant (Das Silo-Modell)
Historisch gesehen galt es als operativer Albtraum, jedem Kunden eine eigene Datenbank zu geben. Der Aufstieg von Serverless-Providern wie Neon und AWS Aurora Serverless v2 hat dies jedoch revolutioniert. Diese Plattformen ermöglichen „Scale-to-Zero“-Funktionen, was bedeutet, dass die Datenbank eines Tenants nichts kostet, wenn sie nicht genutzt wird.
Warum es 2026 gewinnt:
- Null Datenleck-Risiko: Die physische Trennung stellt sicher, dass ein Tenant nicht auf die Daten eines anderen zugreifen kann.
- Anpassbarkeit: Sie können unterschiedliche Migrationen oder Versionen für spezifische Enterprise-Kunden ausführen.
- Branching: Durch „Copy-on-Write“-Branching können Sie neue Tenants sofort onboarden, indem Sie eine Template-Datenbank klonen.
Moderne Innovationen & Best Practices (2025–2026)
Der Release von PostgreSQL 18 hat die Art und Weise, wie wir diese Patterns implementieren, grundlegend verändert. Zwei Features stechen hervor: Natives Asynchronous I/O (AIO) und native UUIDv7-Unterstützung.
Der Wechsel zu UUIDv7
Jahrelang debattierten Entwickler zwischen sequentiellen Integern (schnell, aber unsicher) und zufälligen UUIDv4 (sicher, aber langsam für Indizes). UUIDv7 ist der Standard für 2026, da es zeitlich sortiert ist. Dies verhindert die bei zufälligen UUIDs übliche B-Baum-Index-Fragmentierung und hält Ihre Inserts schnell, selbst wenn Ihr SaaS auf Milliarden von Zeilen anwächst.
Vektor-Isolierung in KI-nativen SaaS
Mit dem Aufstieg von Retrieval-Augmented Generation (RAG) speichern SaaS-Datenbanken nun Vektor-Embeddings. Das „Vector Isolation Pattern“ beinhaltet die Verwendung von Row-Level Security (RLS) auf Vektorspalten, um sicherzustellen, dass ein KI-Agent nur Kontext abruft, der für den spezifischen Tenant relevant ist, und so „KI-Halluzinationen“ mit Daten anderer Kunden verhindert.
Strategien für Datenisolierung und Tenant-Auflösung
Isolierung ist der „heilige Gral“ von SaaS. Im Jahr 2026 hat sich die Branche auf zwei primäre Methoden standardisiert, um sicherzustellen, dass kein Kunde jemals die Daten eines anderen sieht.
Row-Level Security (RLS): Der Goldstandard
Wenn Sie das „Pool“-Modell verwenden, ist Row-Level Security von PostgreSQL obligatorisch. Anstatt manuell tenant_id an jede Query anzuhängen, definieren Sie eine Policy auf Datenbankebene.
-- RLS auf der Tabelle aktivieren
ALTER TABLE orders ENABLE ROW LEVEL SECURITY;
-- Eine Policy erstellen, die den Zugriff basierend auf einer Session-Variable einschränkt
CREATE POLICY tenant_isolation_policy ON orders
USING (tenant_id = current_setting('app.current_tenant')::uuid);Tenant-Auflösung via Middleware
Damit RLS funktioniert, muss Ihre Anwendung der Datenbank „mitteilen“, welcher Tenant gerade aktiv ist. In einem modernen TypeScript-Stack mit Drizzle ORM oder Prisma wird dies in der Request-Middleware gehandhabt.
// middleware/tenant-resolver.ts
import { NextFunction, Request, Response } from 'express';
import { db } from '../db';
export async function tenantMiddleware(req: Request, res: Response, next: NextFunction) {
const tenantId = req.auth.claims.tenant_id; // Aus JWT extrahiert
if (!tenantId) {
return res.status(401).send('Unauthorized');
}
// Eine Transaktion verwenden, um die lokale Variable für diese Verbindung zu setzen
await db.transaction(async (tx) => {
await tx.execute(sql`SET LOCAL app.current_tenant = ${tenantId}`);
// Das Transaktionsobjekt im Request für die Verwendung in Controllern speichern
req.tenantDb = tx;
next();
});
}Warnung: Verwenden Sie SET LOCAL immer innerhalb einer Transaktion. Wenn Sie SET global auf einer gepoolten Verbindung verwenden, könnte die tenant_id an der Verbindung „haften“ bleiben und zum nächsten Benutzer durchsickern – ein Phänomen, das als Pool Contamination bekannt ist.
Skalierungsprobleme und das Noisy-Neighbor-Problem
Wenn Ihr SaaS skaliert, werden Sie irgendwann auf einen „Noisy Neighbor“ stoßen – einen einzelnen Tenant, dessen Nutzung so stark ansteigt, dass er anderen Tenants Ressourcen (CPU, Memory, I/O) entzieht.
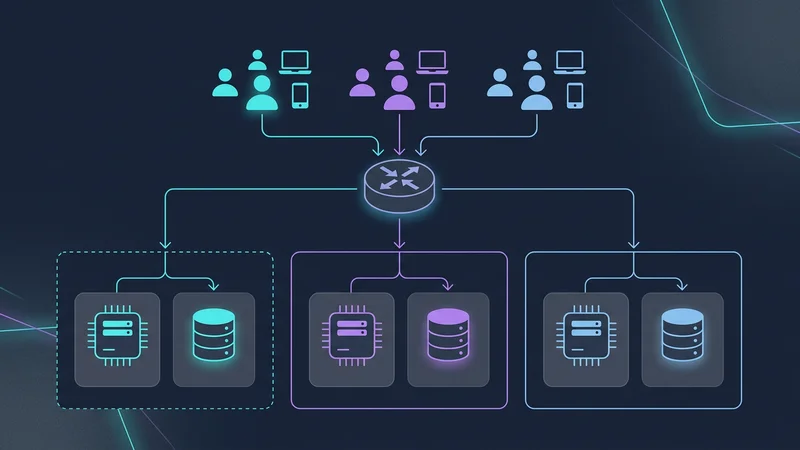
Zellenbasierte Architektur (Cell-Based Architecture)
Um dies abzumildern, verwenden extrem skalierbare SaaS-Anwendungen (wie Slack und Salesforce) eine Cell-Based Architecture. Anstatt einer riesigen Datenbank für 1.000.000 Tenants erstellen Sie „Zellen“. Jede Zelle ist eine eigenständige Einheit (z. B. ein Datenbank-Cluster + Compute), die 50.000 Tenants beherbergt.
- Explosionsradius: Wenn Zelle A ausfällt, sind nur 5 % Ihrer Kunden betroffen.
- Globale Expansion: Sie können Zelle B in der EU und Zelle C in den USA platzieren, um Datenschutzgesetze zur Datenresidenz zu erfüllen.
Distributed SQL für globales SaaS
Für Anwendungen, die eine einzige logische globale Datenbank benötigen, sind Distributed-SQL-Engines wie CockroachDB v25.4 die bevorzugte Wahl. Sie ermöglichen es Ihnen, spezifische Zeilen mithilfe einer regional_by_row-Strategie an geografische Regionen zu „pinnen“, was niedrige Latenzzeiten für Benutzer gewährleistet und gleichzeitig die globale Konsistenz wahrt.
Best Practices für Schema-Migration und Wartung
Die Verwaltung von Migrationen für 10.000 separate Tenant-Schemas ist eine unmögliche manuelle Aufgabe. Automatisierung über Infrastructure-as-Code (IaC) ist der einzige Weg nach vorne.
Automatisierung von Multi-Tenant-Migrationen
Moderne Toolkits wie drizzle-multitenant oder benutzerdefinierte Terraform-Provider ermöglichen es Ihnen, Ihre Datenbank-Schemas als Code zu behandeln. Wenn Sie Ihr „Template-Schema“ aktualisieren, iteriert die CI/CD-Pipeline durch alle Tenant-Datenbanken und wendet die Änderungen an.
# Beispiel: Ausführen von Migrationen über alle Tenant-Schemas hinweg
npx drizzle-kit push:pg --config=./drizzle.config.ts --all-tenantsWichtige Fallstricke, die es zu vermeiden gilt:
- Zufällige UUIDs: Wie erwähnt, vermeiden Sie UUIDv4 für Primärschlüssel. Verwenden Sie UUIDv7.
- Verbindungserschöpfung (Connection Exhaustion): Das Skalieren auf 5.000 Tenants mit separaten Verbindungen wird Ihre DB zum Absturz bringen. Verwenden Sie einen Tenant-aware Connection-Pooler wie Supabase Supavisor oder PgBouncer.
- Fehlende Indizes auf Tenant-Spalten: In einem Shared Schema muss jeder einzelne Index
tenant_idals erste oder zweite Spalte enthalten, um sicherzustellen, dass der Query-Optimizer Daten effizient filtern kann.
Häufig gestellte Fragen (FAQ)
Was ist der Unterschied zwischen Silo-, Bridge- und Pool-Datenbankmodellen?
Das Silo-Modell bietet jedem Tenant eine dedizierte Datenbankinstanz, was maximale Isolierung, aber höheren Verwaltungsaufwand bedeutet. Das Bridge-Modell nutzt eine gemeinsame Datenbankinstanz mit separaten Schemas für jeden Tenant und balanciert so Isolierung und Kosten. Das Pool-Modell nutzt ein gemeinsames Schema, in dem alle Tenant-Daten in denselben Tabellen liegen, getrennt durch eine Tenant-ID, was die höchste Kosteneffizienz, aber auch das größte Risiko bietet.
Wie gewährleistet man die Datenisolierung in einer gemeinsamen Multi-Tenant-Datenbank?
Datenisolierung wird primär durch Row-Level Security (RLS) auf Datenbankebene sichergestellt, was den Zugriff basierend auf dem Session-Kontext des Benutzers einschränkt. Zusätzlich muss die Middleware auf Anwendungsebene die Tenant-Auflösung strikt erzwingen, indem sie die korrekte tenant_id in jede Abfrage oder Session-Variable injiziert. Die Verwendung zeitlich sortierter Identifikatoren wie UUIDv7 hilft ebenfalls, die Performance und Organisation innerhalb gemeinsamer Indizes aufrechtzuerhalten.
Welche Datenbankarchitektur ist am besten für eine skalierende SaaS-Anwendung geeignet?
Für SaaS-Anwendungen in der Frühphase ist das Pool-Modell mit RLS aufgrund der geringen Kosten und Einfachheit meist am besten. Wenn Sie in den Enterprise-Markt skalieren, wird eine Hybrid- oder Cell-Based-Architektur bevorzugt, bei der die meisten Benutzer in einem gemeinsamen Pool bleiben, während hochwertige Enterprise-Kunden in dedizierte Silos migriert werden, um bessere Performance und Compliance zu gewährleisten.
Wie handhabt man Schema-Migrationen für Tausende von Tenants?
Schema-Migrationen sollten mithilfe von Infrastructure-as-Code (IaC) und automatisierten Migrations-Runnern gehandhabt werden, die Änderungen parallel über alle Schemas hinweg ausführen können. Tools wie Drizzle ORM oder spezialisierte CI/CD-Skripte werden eingesetzt, um sicherzustellen, dass Migrationen idempotent sind und Fehler bei der Migration eines Tenants nicht den gesamten Deployment-Prozess stoppen.
Kann Multi-Tenancy die Datenbank-Performance und Latenz beeinflussen?
Ja, Multi-Tenancy kann zum Noisy-Neighbor-Problem führen, bei dem die hohe Ressourcennutzung eines Tenants die Abfragen für andere verlangsamt. Darüber hinaus kann ohne ordnungsgemäße Indizierung auf tenant_id und den Einsatz von Connection-Poolern der Overhead für die Verwaltung Tausender Tenant-Kontexte die Latenz erheblich erhöhen und das Risiko einer Verbindungserschöpfung bergen.
Fazit
Datenbankdesign für SaaS in den Jahren 2025–2026 bedeutet nicht mehr nur die Wahl zwischen SQL und NoSQL. Es geht darum, eine Strategie zu wählen, die mit Ihren Geschäftszielen übereinstimmt.
Wenn Sie eine hochvolumige Consumer-App bauen, bietet das Shared Schema (Pool) Modell mit PostgreSQL 18 und RLS die beste Performance und Kostenersparnis. Wenn Sie den Enterprise-Markt anvisieren, bietet das Serverless Silo Modell die Isolierung und Compliance, die Ihre Kunden fordern, ohne den historischen Aufwand für die Verwaltung Tausender Server.
Indem Sie sich auf UUIDv7 standardisieren, Cell-Based Architectures für die Skalierung implementieren und automatisierte Migrations-Toolkits nutzen, können Sie ein SaaS-Backend bauen, das nicht nur heute robust ist, sondern auch für die Anforderungen des nächsten Jahrzehnts bereit ist.