Introducere: Evoluția Multi-Tenant
În peisajul în continuă evoluție al Software-as-a-Service (SaaS), baza de date nu mai este doar un motor de stocare — este coloana vertebrală arhitecturală care determină scalabilitatea, securitatea și marginile de profit ale aplicației tale. Pe măsură ce avansăm prin 2025 și spre 2026, abordarea „universală” (one-size-fits-all) a proiectării bazelor de date a fost înlocuită de modele sofisticate care echilibrează izolarea clienților (tenants) cu eficiența operațională.
Echipele moderne de inginerie SaaS se îndepărtează de bazele de date monolitice către arhitecturi mai granulare, „conștiente de clienți” (tenant-aware). Odată cu lansarea PostgreSQL 18 și maturizarea tehnologiilor de baze de date serverless, dezvoltatorii au acum la dispoziție instrumente care anterior erau rezervate companiilor de talia FAANG. Indiferent dacă construiești un instrument B2B de nișă sau o platformă globală pentru întreprinderi, alegerea modelului potrivit de proiectare a bazei de date este cea mai critică decizie tehnică pe care o vei lua.
Modele de arhitectură a bazelor de date Multi-Tenant
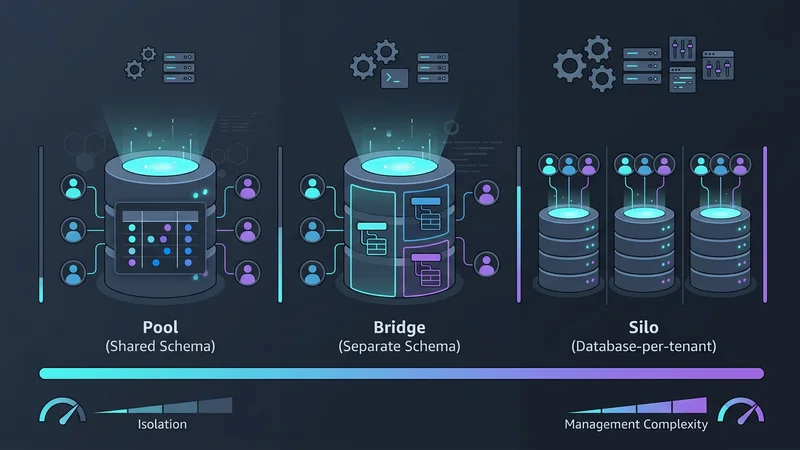
Alegerea unui model de multi-tenancy implică un compromis între trei factori: Izolare, Scalabilitate și Cost. În 2026, clasificăm aceste modele în trei categorii principale: Pool, Bridge și Silo.
Modelul 1: Bază de date partajată, Schemă partajată (Modelul Pool)
Modelul „Pool” este cea mai comună arhitectură pentru aplicațiile SaaS cu volum mare și costuri reduse. În acest model, toți clienții partajează aceeași bază de date și aceleași tabele. Datele sunt separate logic printr-o coloană tenant_id în fiecare tabel.
Avantaje:
- Eficiența costurilor: Plătești doar pentru o singură instanță de bază de date.
- Agregare simplă: Rularea analizelor pe toți clienții este directă.
- Mentenanță: O singură schemă de migrat, un singur set de indecși de gestionat.
Dezavantaje:
- Efectul „Noisy Neighbor”: Un singur utilizator cu activitate intensă poate degrada performanța pentru toți ceilalți.
- Risc de securitate: Un bug în clauza
WHEREa aplicației tale ar putea duce la scurgerea datelor.
Modelul 2: Bază de date partajată, Scheme separate (Modelul Bridge)
Folosit adesea în HealthTech sau FinTech, modelul „Bridge” oferă o cale de mijloc. Fiecare client primește propria schemă (de exemplu, tenant_a.orders, tenant_b.orders) în cadrul unei singure instanțe fizice de bază de date.
Acest model este preferat în 2025 pentru medii cu cerințe stricte de conformitate, cum ar fi aplicațiile conforme HIPAA. Acesta oferă separare logică, făcând mai dificilă scurgerea datelor între clienți, permițând în același timp echipei de infrastructură să gestioneze un singur cluster de baze de date.
Modelul 3: Bază de date per client (Modelul Silo)
Din punct de vedere istoric, oferirea unei baze de date proprii fiecărui client era considerată un coșmar operațional. Cu toate acestea, ascensiunea furnizorilor serverless precum Neon și AWS Aurora Serverless v2 a revoluționat acest aspect. Aceste platforme permit capacități de „scale-to-zero”, ceea ce înseamnă că baza de date a unui client nu costă nimic atunci când nu este utilizată.
De ce câștigă teren în 2026:
- Scurgere zero: Separarea fizică garantează că un client nu poate accesa datele altuia.
- Personalizare: Poți rula migrări sau versiuni diferite pentru clienți enterprise specifici.
- Branching: Folosind ramificarea „copy-on-write”, poți înrola clienți noi instantaneu prin clonarea unei baze de date șablon.
Inovații moderne și bune practici (2025–2026)
Lansarea PostgreSQL 18 a schimbat fundamental modul în care implementăm aceste modele. Două caracteristici ies în evidență: Native Asynchronous I/O (AIO) și suportul nativ pentru UUIDv7.
Trecerea la UUIDv7
Ani de zile, dezvoltatorii au dezbătut între numere întregi secvențiale (rapide, dar nesigure) și UUIDv4 aleatorii (sigure, dar lente pentru indecși). UUIDv7 este standardul anului 2026 deoarece este ordonat temporal. Acest lucru previne fragmentarea indexului B-tree, comună la UUID-urile aleatorii, menținând inserțiile rapide chiar și atunci când SaaS-ul tău crește la miliarde de rânduri.
Izolarea vectorilor în SaaS AI-Native
Odată cu ascensiunea Retrieval-Augmented Generation (RAG), bazele de date SaaS stochează acum vector embeddings. „Modelul de izolare a vectorilor” implică utilizarea Row-Level Security (RLS) pe coloanele vectoriale pentru a asigura că un agent AI preia doar contextul relevant pentru clientul specific, prevenind „halucinațiile AI” care implică datele altor clienți.
Strategii de izolare a datelor și rezolvare a clienților
Izolarea este „sfântul graal” al SaaS-ului. În 2026, industria s-a standardizat pe două metode principale pentru a se asigura că niciun client nu vede vreodată datele altuia.
Row-Level Security (RLS): Standardul de aur
Dacă folosești modelul „Pool”, Row-Level Security din PostgreSQL este obligatoriu. În loc să adaugi manual tenant_id la fiecare interogare, definești o politică la nivelul bazei de date.
-- Activează RLS pe tabelă
ALTER TABLE orders ENABLE ROW LEVEL SECURITY;
-- Creează o politică ce restricționează accesul pe baza unei variabile de sesiune
CREATE POLICY tenant_isolation_policy ON orders
USING (tenant_id = current_setting('app.current_tenant')::uuid);Rezolvarea clienților prin Middleware
Pentru ca RLS să funcționeze, aplicația ta trebuie să „spună” bazei de date care client este activ în prezent. Într-o stivă modernă TypeScript folosind Drizzle ORM sau Prisma, acest lucru este gestionat în middleware-ul cererii.
// middleware/tenant-resolver.ts
import { NextFunction, Request, Response } from 'express';
import { db } from '../db';
export async function tenantMiddleware(req: Request, res: Response, next: NextFunction) {
const tenantId = req.auth.claims.tenant_id; // Extras din JWT
if (!tenantId) {
return res.status(401).send('Unauthorized');
}
// Folosește o tranzacție pentru a seta variabila locală pentru această conexiune
await db.transaction(async (tx) => {
await tx.execute(sql`SET LOCAL app.current_tenant = ${tenantId}`);
// Stochează obiectul de tranzacție în cerere pentru a fi utilizat în controllere
req.tenantDb = tx;
next();
});
}Atenție: Folosește întotdeauna SET LOCAL în cadrul unei tranzacții. Dacă folosești SET global pe o conexiune partajată (pooled), tenant_id s-ar putea „lipi” de conexiune și s-ar putea scurge la următorul utilizator — un fenomen cunoscut sub numele de Pool Contamination.
Provocări de scalare și problema „Noisy Neighbor”
Pe măsură ce SaaS-ul tău se scalează, vei întâlni inevitabil un „Noisy Neighbor” — un singur client a cărui utilizare crește atât de mult încât privează ceilalți clienți de resurse (CPU, memorie, I/O).
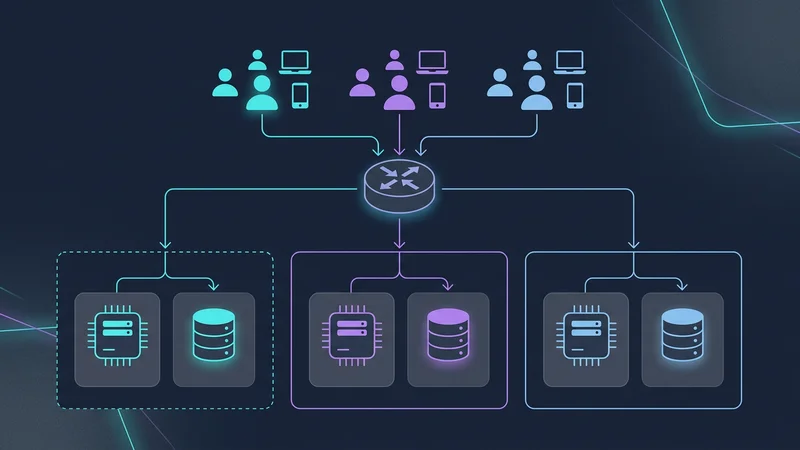
Arhitectura bazată pe celule (Cell-Based Architecture)
Pentru a atenua acest lucru, aplicațiile SaaS la scară ultra-mare (precum Slack și Salesforce) folosesc Arhitectura bazată pe celule. În loc de o singură bază de date gigantică pentru 1.000.000 de clienți, creezi „celule”. Fiecare celulă este o unitate de sine stătătoare (de exemplu, un cluster de baze de date + calcul) care găzduiește 50.000 de clienți.
- Raza de impact (Blast Radius): Dacă Celula A cade, doar 5% dintre clienții tăi sunt afectați.
- Expansiune globală: Poți plasa Celula B în UE și Celula C în SUA pentru a respecta legile privind rezidența datelor.
Distributed SQL pentru SaaS Global
Pentru aplicațiile care necesită o singură bază de date globală logică, motoarele Distributed SQL precum CockroachDB v25.4 sunt alegerea preferată. Acestea îți permit să „fixezi” rânduri specifice în regiuni geografice folosind o strategie regional_by_row, asigurând latență scăzută pentru utilizatori și menținând în același timp consistența globală.
Migrarea schemei și bune practici de mentenanță
Gestionarea migrărilor pentru 10.000 de scheme separate de clienți este o sarcină manuală imposibilă. Automatizarea prin Infrastructure-as-Code (IaC) este singura cale de urmat.
Automatizarea migrărilor Multi-Tenant
Seturile de instrumente moderne precum drizzle-multitenant sau furnizorii Terraform personalizați îți permit să tratezi schemele bazei de date ca pe cod. Când actualizezi „Schema Șablon”, pipeline-ul CI/CD parcurge toate bazele de date ale clienților și aplică modificările.
# Exemplu: Rularea migrărilor pe toate schemele clienților
npx drizzle-kit push:pg --config=./drizzle.config.ts --all-tenantsGreșeli cheie de evitat:
- UUID-uri aleatorii: După cum am menționat, evită UUIDv4 pentru cheile primare. Folosește UUIDv7.
- Epuizarea conexiunilor: Scalarea la 5.000 de clienți cu conexiuni separate îți va bloca baza de date. Folosește un pooler de conexiuni conștient de clienți, cum ar fi Supabase Supavisor sau PgBouncer.
- Lipsa indecșilor pe coloanele de client: Într-o schemă partajată, fiecare index trebuie să includă
tenant_idca primă sau a doua coloană pentru a asigura că optimizatorul de interogări poate filtra datele eficient.
Întrebări frecvente
Care este diferența între modelele de baze de date silo, bridge și pool?
Modelul Silo oferă fiecărui client o instanță dedicată de bază de date, oferind izolare maximă, dar costuri de gestionare mai mari. Modelul Bridge folosește o instanță de bază de date partajată cu scheme separate pentru fiecare client, echilibrând izolarea și costul. Modelul Pool folosește o schemă partajată unde toate datele clienților se află în aceleași tabele, separate de un ID de client, oferind cea mai mare eficiență a costurilor, dar și cel mai mare risc.
Cum asiguri izolarea datelor într-o bază de date multi-tenant partajată?
Izolarea datelor este asigurată în principal prin Row-Level Security (RLS) la nivelul bazei de date, care restricționează accesul pe baza contextului sesiunii utilizatorului. În plus, middleware-ul la nivel de aplicație trebuie să impună strict rezolvarea clientului prin injectarea corectă a tenant_id în fiecare interogare sau variabilă de sesiune. Utilizarea identificatorilor ordonați temporal, cum ar fi UUIDv7, ajută de asemenea la menținerea performanței și organizării în cadrul indecșilor partajați.
Ce arhitectură de bază de date este cea mai bună pentru o aplicație SaaS în curs de scalare?
Pentru un SaaS în stadiu incipient, modelul Pool cu RLS este de obicei cel mai bun datorită costului scăzut și simplității. Pe măsură ce te extinzi către clienți enterprise, este preferată o arhitectură Hibridă sau bazată pe celule, unde majoritatea utilizatorilor rămân într-un pool partajat, în timp ce clienții enterprise de mare valoare sunt migrați către silozuri dedicate pentru performanță și conformitate mai bune.
Cum gestionezi migrările de schemă pentru mii de clienți?
Migrările de schemă ar trebui gestionate folosind Infrastructure-as-Code (IaC) și rulmenți de migrare automatizați care pot executa modificările în paralel pe toate schemele. Instrumente precum Drizzle ORM sau scripturi CI/CD specializate sunt folosite pentru a asigura că migrările sunt idempotente și că eșecurile în migrarea unui client nu opresc întregul proces de desfășurare.
Poate multi-tenancy să afecteze performanța și latența bazei de date?
Da, multi-tenancy poate duce la problema Noisy Neighbor, unde utilizarea intensă a resurselor de către un client încetinește interogările pentru ceilalți. Mai mult, fără o indexare adecvată pe tenant_id și utilizarea poolerelor de conexiuni, costul gestionării a mii de contexte de clienți poate crește semnificativ latența și riscul de epuizare a conexiunilor.
Concluzie
Proiectarea bazelor de date pentru SaaS în 2025–2026 nu mai înseamnă doar alegerea între SQL și NoSQL. Este vorba despre alegerea unei strategii care să se alinieze cu obiectivele tale de afaceri.
Dacă construiești o aplicație de consum cu volum mare, modelul Shared Schema (Pool) cu PostgreSQL 18 și RLS oferă cea mai bună performanță și cost. Dacă vizezi piața enterprise, modelul Serverless Silo oferă izolarea și conformitatea pe care clienții tăi le cer, fără costurile istorice de gestionare a mii de servere.
Prin standardizarea pe UUIDv7, implementarea Arhitecturilor bazate pe celule pentru scară și utilizarea seturilor de instrumente de migrare automată, poți construi un backend SaaS care nu este doar robust astăzi, ci pregătit pentru cerințele deceniului următor.