Introdução: A Evolução do Multi-Tenant
No cenário em rápida evolução do Software-as-a-Service (SaaS), o banco de dados não é mais apenas um motor de armazenamento — ele é a espinha dorsal arquitetural que determina a escalabilidade, a segurança e as margens de lucro da sua aplicação. À medida que avançamos por 2025 e entramos em 2026, a abordagem "tamanho único" para o design de bancos de dados foi substituída por padrões sofisticados que equilibram o isolamento de tenants com a eficiência operacional.
As equipes modernas de engenharia SaaS estão se afastando de bancos de dados monolíticos em direção a arquiteturas mais granulares e "tenant-aware" (conscientes de tenants). Com o lançamento do PostgreSQL 18 e o amadurecimento das tecnologias de banco de dados serverless, os desenvolvedores agora têm ferramentas que anteriormente eram reservadas para empresas de escala FAANG. Esteja você construindo uma ferramenta B2B de nicho ou uma plataforma corporativa global, escolher o padrão de design de banco de dados correto é a decisão técnica mais crítica que você tomará.
Padrões de Arquitetura de Banco de Dados Multi-Tenant
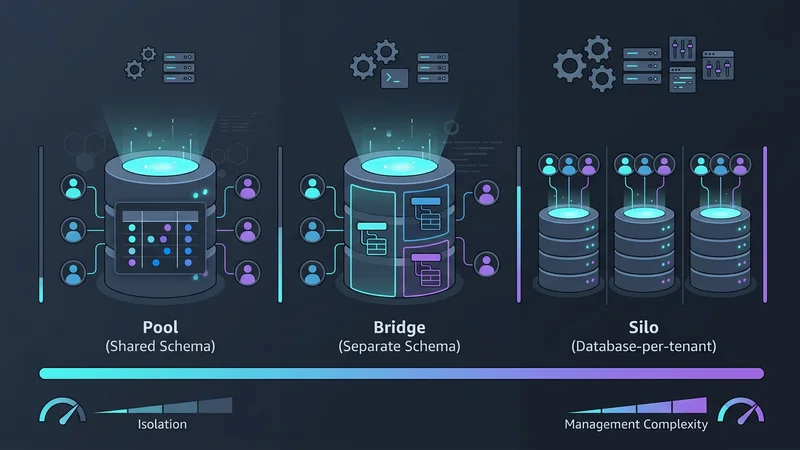
Escolher um modelo de multi-tenancy envolve um trade-off entre três fatores: Isolamento, Escalabilidade e Custo. Em 2026, categorizamos estes em três padrões primários: o Pool, o Bridge e o Silo.
Padrão 1: Banco de Dados Compartilhado, Esquema Compartilhado (O Modelo Pool)
O modelo "Pool" é a arquitetura mais comum para aplicações SaaS de alto volume e baixo custo. Neste padrão, todos os tenants compartilham o mesmo banco de dados e as mesmas tabelas. Os dados são separados logicamente por uma coluna tenant_id em cada tabela.
Prós:
- Eficiência de Custo: Você paga apenas por uma instância de banco de dados.
- Agregação Simples: Executar analytics em todos os clientes é direto.
- Manutenção: Um único esquema para migrar, um conjunto de índices para gerenciar.
Contras:
- Efeito Noisy Neighbor (Vizinho Barulhento): Um único usuário pesado pode degradar o desempenho para todos.
- Risco de Segurança: Um bug na cláusula
WHEREda sua aplicação pode levar ao vazamento de dados.
Padrão 2: Banco de Dados Compartilhado, Esquemas Separados (O Modelo Bridge)
Frequentemente usado em HealthTech ou FinTech, o modelo "Bridge" oferece um meio-termo. Cada tenant recebe seu próprio esquema (ex: tenant_a.orders, tenant_b.orders) dentro de uma única instância física de banco de dados.
Este modelo é favorecido em 2025 para ambientes com alta carga de conformidade, como apps compatíveis com HIPAA. Ele fornece separação lógica, tornando mais difícil o vazamento de dados entre tenants, enquanto ainda permite que a equipe de infraestrutura gerencie um único cluster de banco de dados.
Padrão 3: Banco de Dados por Tenant (O Modelo Silo)
Historicamente, dar a cada cliente seu próprio banco de dados era considerado um pesadelo operacional. No entanto, o surgimento de provedores serverless como Neon e AWS Aurora Serverless v2 revolucionou isso. Essas plataformas permitem recursos de "scale-to-zero", o que significa que o banco de dados de um tenant não custa nada quando não está sendo usado.
Por que está vencendo em 2026:
- Vazamento Zero: A separação física garante que um tenant não possa acessar os dados de outro.
- Customização: Você pode executar migrações ou versões diferentes para clientes corporativos específicos.
- Branching: Usando o branching "copy-on-write", você pode integrar novos tenants instantaneamente clonando um banco de dados de template.
Inovações Modernas e Melhores Práticas (2025–2026)
O lançamento do PostgreSQL 18 mudou fundamentalmente a forma como implementamos esses padrões. Dois recursos se destacam: I/O Assíncrono Nativo (AIO) e suporte nativo a UUIDv7.
A Mudança para o UUIDv7
Por anos, os desenvolvedores debateram entre inteiros sequenciais (rápidos, mas inseguros) e UUIDv4 aleatórios (seguros, mas lentos para índices). O UUIDv7 é o padrão de 2026 porque é ordenado no tempo. Isso evita a fragmentação do índice B-tree comum com UUIDs aleatórios, mantendo seus inserts rápidos mesmo que seu SaaS cresça para bilhões de linhas.
Isolamento de Vetores em SaaS Nativo de IA
Com a ascensão da Geração Aumentada de Recuperação (RAG), os bancos de dados SaaS agora estão armazenando embeddings de vetores. O "Padrão de Isolamento de Vetores" envolve o uso de Row-Level Security (RLS) em colunas de vetores para garantir que um agente de IA recupere apenas o contexto relevante para o tenant específico, evitando "Alucinações de IA" envolvendo dados de outros clientes.
Estratégias de Isolamento de Dados e Resolução de Tenant
O isolamento é o "santo graal" do SaaS. Em 2026, a indústria padronizou dois métodos primários para garantir que nenhum cliente veja os dados de outro.
Row-Level Security (RLS): O Padrão Ouro
Se você estiver usando o modelo "Pool", o Row-Level Security do PostgreSQL é obrigatório. Em vez de anexar manualmente o tenant_id a cada consulta, você define uma política no nível do banco de dados.
-- Habilita RLS na tabela
ALTER TABLE orders ENABLE ROW LEVEL SECURITY;
-- Cria uma política que restringe o acesso com base em uma variável de sessão
CREATE POLICY tenant_isolation_policy ON orders
USING (tenant_id = current_setting('app.current_tenant')::uuid);Resolução de Tenant via Middleware
Para fazer o RLS funcionar, sua aplicação deve "dizer" ao banco de dados qual tenant está ativo no momento. Em uma stack TypeScript moderna usando Drizzle ORM ou Prisma, isso é tratado no middleware da requisição.
// middleware/tenant-resolver.ts
import { NextFunction, Request, Response } from 'express';
import { db } from '../db';
export async function tenantMiddleware(req: Request, res: Response, next: NextFunction) {
const tenantId = req.auth.claims.tenant_id; // Extraído do JWT
if (!tenantId) {
return res.status(401).send('Unauthorized');
}
// Usa uma transação para definir a variável local para esta conexão
await db.transaction(async (tx) => {
await tx.execute(sql`SET LOCAL app.current_tenant = ${tenantId}`);
// Armazena o objeto de transação na requisição para uso nos controllers
req.tenantDb = tx;
next();
});
}Aviso: Sempre use SET LOCAL dentro de uma transação. Se você usar SET globalmente em uma conexão poolada, o tenant_id pode "ficar preso" à conexão e vazar para o próximo usuário — um fenômeno conhecido como Pool Contamination (Contaminação de Pool).
Desafios de Escalabilidade e o Problema do Noisy Neighbor
À medida que seu SaaS escala, você eventualmente encontrará um "Noisy Neighbor" — um único tenant cujo uso aumenta tanto que priva outros tenants de recursos (CPU, Memória, I/O).
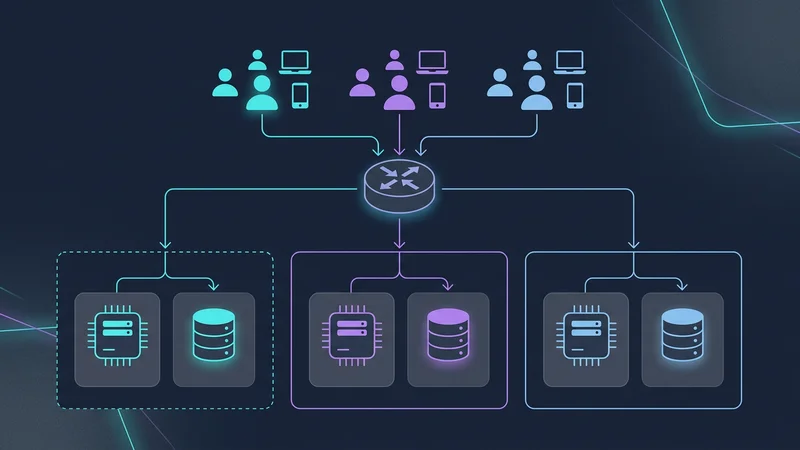
Arquitetura Baseada em Células (Cell-Based Architecture)
Para mitigar isso, aplicações SaaS de ultra-escala (como Slack e Salesforce) usam a Arquitetura Baseada em Células. Em vez de um banco de dados gigante para 1.000.000 de tenants, você cria "células". Cada célula é uma unidade independente (ex: um cluster de banco de dados + computação) que hospeda 50.000 tenants.
- Raio de Explosão (Blast Radius): Se a Célula A cair, apenas 5% dos seus clientes são afetados.
- Expansão Global: Você pode colocar a Célula B na UE e a Célula C nos EUA para satisfazer as leis de residência de dados.
SQL Distribuído para SaaS Global
Para aplicações que exigem um único banco de dados lógico global, mecanismos de SQL Distribuído como o CockroachDB v25.4 são a escolha preferida. Eles permitem que você "prenda" linhas específicas a regiões geográficas usando uma estratégia regional_by_row, garantindo baixa latência para os usuários enquanto mantém a consistência global.
Melhores Práticas de Migração de Esquema e Manutenção
Gerenciar migrações para 10.000 esquemas de tenants separados é uma tarefa manual impossível. A automação via Infraestrutura como Código (IaC) é o único caminho a seguir.
Automatizando Migrações Multi-Tenant
Toolkits modernos como drizzle-multitenant ou provedores Terraform personalizados permitem que você trate seus esquemas de banco de dados como código. Quando você atualiza seu "Esquema de Template", o pipeline de CI/CD itera por todos os bancos de dados de tenants e aplica as alterações.
# Exemplo: Executando migrações em todos os esquemas de tenants
npx drizzle-kit push:pg --config=./drizzle.config.ts --all-tenantsPrincipais Armadilhas a Evitar:
- UUIDs Aleatórios: Como mencionado, evite UUIDv4 para chaves primárias. Use UUIDv7.
- Exaustão de Conexões: Escalar para 5.000 tenants com conexões separadas irá travar seu banco de dados. Use um pooler de conexões consciente de tenant como o Supabase Supavisor ou PgBouncer.
- Falta de Índices em Colunas de Tenant: Em um esquema compartilhado, cada índice deve incluir o
tenant_idcomo a primeira ou segunda coluna para garantir que o otimizador de consultas possa filtrar os dados de forma eficiente.
Perguntas Frequentes
Qual é a diferença entre os modelos de banco de dados silo, bridge e pool?
O modelo Silo fornece a cada tenant uma instância de banco de dados dedicada, oferecendo isolamento máximo, mas maior sobrecarga de gerenciamento. O modelo Bridge usa uma instância de banco de dados compartilhada com esquemas separados para cada tenant, equilibrando isolamento e custo. O modelo Pool usa um esquema compartilhado onde todos os dados dos tenants residem nas mesmas tabelas, separados por um ID de tenant, oferecendo a maior eficiência de custo, mas o maior risco.
Como garantir o isolamento de dados em um banco de dados multi-tenant compartilhado?
O isolamento de dados é garantido principalmente através do Row-Level Security (RLS) no nível do banco de dados, que restringe o acesso com base no contexto da sessão do usuário. Além disso, o middleware no nível da aplicação deve aplicar rigorosamente a resolução de tenant injetando o tenant_id correto em cada consulta ou variável de sessão. O uso de identificadores ordenados no tempo como o UUIDv7 também ajuda a manter o desempenho e a organização dentro de índices compartilhados.
Qual arquitetura de banco de dados é melhor para uma aplicação SaaS em crescimento?
Para SaaS em estágio inicial, o modelo Pool com RLS geralmente é o melhor devido ao seu baixo custo e simplicidade. À medida que você escala para clientes corporativos, uma arquitetura Híbrida ou Baseada em Células é preferível, onde a maioria dos usuários permanece em um pool compartilhado enquanto clientes corporativos de alto valor são migrados para silos dedicados para melhor desempenho e conformidade.
Como lidar com migrações de esquema para milhares de tenants?
As migrações de esquema devem ser tratadas usando Infraestrutura como Código (IaC) e executores de migração automatizados que podem executar alterações em paralelo em todos os esquemas. Ferramentas como Drizzle ORM ou scripts de CI/CD especializados são usados para garantir que as migrações sejam idempotentes e que falhas na migração de um tenant não interrompam todo o processo de deploy.
A multi-tenancy pode afetar o desempenho e a latência do banco de dados?
Sim, a multi-tenancy pode levar ao problema do Noisy Neighbor, onde o uso pesado de recursos de um tenant retarda as consultas para outros. Além disso, sem a indexação adequada no tenant_id e o uso de poolers de conexões, a sobrecarga de gerenciar milhares de contextos de tenants pode aumentar significativamente a latência e arriscar a exaustão de conexões.
Conclusão
O design de banco de dados para SaaS em 2025–2026 não se trata mais apenas de escolher entre SQL e NoSQL. Trata-se de escolher uma estratégia que se alinhe aos seus objetivos de negócio.
Se você está construindo um app de consumo de alto volume, o modelo de Esquema Compartilhado (Pool) com PostgreSQL 18 e RLS oferece o melhor desempenho e custo. Se você está visando o mercado corporativo, o modelo de Silo Serverless fornece o isolamento e a conformidade que seus clientes exigem sem a sobrecarga histórica de gerenciar milhares de servidores.
Ao padronizar no UUIDv7, implementar Arquiteturas Baseadas em Células para escala e aproveitar toolkits de migração automatizada, você pode construir um backend SaaS que não seja apenas robusto hoje, mas pronto para as demandas da próxima década.