Introductie: De Multi-Tenant Evolutie
In het snel veranderende landschap van Software-as-a-Service (SaaS) is de database niet langer slechts een opslagmedium—het is de architecturale ruggengraat die de schaalbaarheid, beveiliging en winstmarges van uw applicatie bepaalt. Terwijl we 2025 passeren en 2026 ingaan, is de "one-size-fits-all" benadering van database-ontwerp vervangen door geavanceerde patronen die tenant-isolatie in evenwicht brengen met operationele efficiëntie.
Moderne SaaS-engineeringteams stappen af van monolithische databases ten gunste van meer granulaire, "tenant-aware" architecturen. Met de release van PostgreSQL 18 en de volwassenwording van serverless databasetechnologieën hebben ontwikkelaars nu tools tot hun beschikking die voorheen waren voorbehouden aan ondernemingen op FAANG-schaal. Of u nu een gespecialiseerde B2B-tool bouwt of een wereldwijd enterprise-platform, het kiezen van het juiste databaseontwerppatroon is de meest kritische technische beslissing die u zult nemen.
Multi-Tenant Database Architectuurpatronen
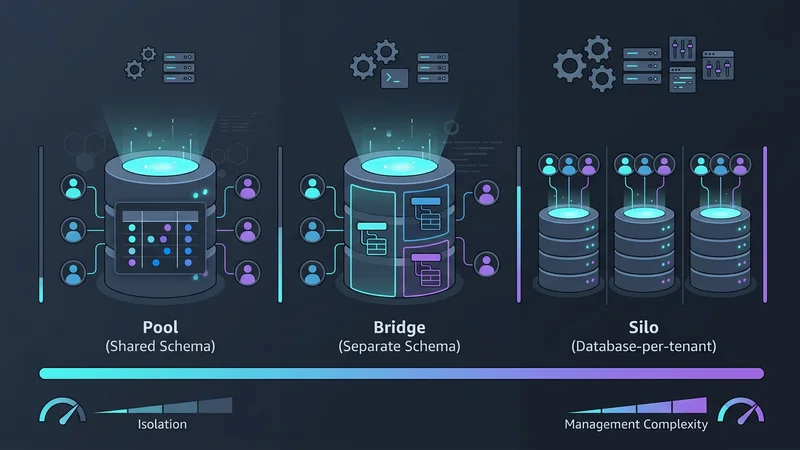
Het kiezen van een multi-tenancy model vereist een afweging tussen drie factoren: Isolatie, Schaalbaarheid en Kosten. In 2026 categoriseren we deze in drie primaire patronen: de Pool, de Bridge en de Silo.
Patroon 1: Gedeelde Database, Gedeeld Schema (Het Pool-model)
Het "Pool"-model is de meest voorkomende architectuur voor SaaS-applicaties met een hoog volume en lage kosten. In dit patroon delen alle tenants dezelfde database en dezelfde tabellen. Gegevens worden logisch gescheiden door een tenant_id kolom in elke tabel.
Voordelen:
- Kostenefficiëntie: U betaalt slechts voor één database-instantie.
- Eenvoudige Aggregatie: Het uitvoeren van analyses over alle klanten heen is ongecompliceerd.
- Onderhoud: Eén schema om te migreren, één set indexen om te beheren.
Nadelen:
- Noisy Neighbor-effect: Eén zware gebruiker kan de prestaties voor iedereen verslechteren.
- Beveiligingsrisico: Een bug in de
WHERE-clausule van uw applicatie kan leiden tot datalekken.
Patroon 2: Gedeelde Database, Aparte Schema's (Het Bridge-model)
Vaak gebruikt in HealthTech of FinTech, biedt het "Bridge"-model een middenweg. Elke tenant krijgt zijn eigen schema (bijv. tenant_a.orders, tenant_b.orders) binnen een enkele fysieke database-instantie.
Dit model is in 2025 favoriet voor omgevingen met strikte compliance-eisen, zoals HIPAA-conforme apps. Het biedt logische scheiding, waardoor het moeilijker is voor data om tussen tenants te lekken, terwijl het infrastructuurteam nog steeds een enkel databasecluster kan beheren.
Patroon 3: Database-per-Tenant (Het Silo-model)
Historisch gezien werd het geven van een eigen database aan elke klant beschouwd als een operationele nachtmerrie. De opkomst van serverless providers zoals Neon en AWS Aurora Serverless v2 heeft dit echter gerevolutioneerd. Deze platforms maken "scale-to-zero" mogelijkheden mogelijk, wat betekent dat de database van een tenant niets kost wanneer deze niet wordt gebruikt.
Waarom het wint in 2026:
- Nul Lekkage: Fysieke scheiding zorgt ervoor dat de ene tenant geen toegang heeft tot de gegevens van de andere.
- Maatwerk: U kunt verschillende migraties of versies draaien voor specifieke enterprise-klanten.
- Branching: Met behulp van "copy-on-write" branching kunt u nieuwe tenants direct onboarden door een template-database te clonen.
Moderne Innovaties & Best Practices (2025–2026)
De release van PostgreSQL 18 heeft de manier waarop we deze patronen implementeren fundamenteel veranderd. Twee functies springen eruit: Native Asynchronous I/O (AIO) en native UUIDv7 ondersteuning.
De verschuiving naar UUIDv7
Jarenlang debatteerden ontwikkelaars tussen sequentiële integers (snel maar onveilig) en willekeurige UUIDv4 (veilig maar traag voor indexen). UUIDv7 is de standaard voor 2026 omdat het tijdgeordend is. Dit voorkomt de B-tree indexfragmentatie die gebruikelijk is bij willekeurige UUID's, waardoor uw inserts snel blijven, zelfs als uw SaaS groeit naar miljarden rijen.
Vector-isolatie in AI-Native SaaS
Met de opkomst van Retrieval-Augmented Generation (RAG) slaan SaaS-databases nu vector embeddings op. Het "Vector Isolation Pattern" omvat het gebruik van Row-Level Security (RLS) op vectorkolommen om ervoor te zorgen dat een AI-agent alleen context ophaalt die relevant is voor de specifieke tenant, wat "AI-hallucinaties" met gegevens van andere klanten voorkomt.
Gegevensisolatie en Tenant-resolutie Strategieën
Isolatie is de "heilige graal" van SaaS. In 2026 is de industrie gestandaardiseerd op twee primaire methoden om ervoor te zorgen dat geen enkele klant ooit de gegevens van een ander ziet.
Row-Level Security (RLS): De Gouden Standaard
Als u het "Pool"-model gebruikt, is PostgreSQL's Row-Level Security verplicht. In plaats van handmatig tenant_id aan elke query toe te voegen, definieert u een beleid op databaseniveau.
-- Schakel RLS in op de tabel
ALTER TABLE orders ENABLE ROW LEVEL SECURITY;
-- Maak een beleid dat de toegang beperkt op basis van een sessievariabele
CREATE POLICY tenant_isolation_policy ON orders
USING (tenant_id = current_setting('app.current_tenant')::uuid);Tenant-resolutie via Middleware
Om RLS te laten werken, moet uw applicatie de database "vertellen" welke tenant momenteel actief is. In een moderne TypeScript stack met Drizzle ORM of Prisma wordt dit afgehandeld in de request middleware.
// middleware/tenant-resolver.ts
import { NextFunction, Request, Response } from 'express';
import { db } from '../db';
export async function tenantMiddleware(req: Request, res: Response, next: NextFunction) {
const tenantId = req.auth.claims.tenant_id; // Geëxtraheerd uit JWT
if (!tenantId) {
return res.status(401).send('Unauthorized');
}
// Gebruik een transactie om de lokale variabele voor deze verbinding in te stellen
await db.transaction(async (tx) => {
await tx.execute(sql`SET LOCAL app.current_tenant = ${tenantId}`);
// Sla het transactie-object op in het request voor gebruik in controllers
req.tenantDb = tx;
next();
});
}Waarschuwing: Gebruik altijd SET LOCAL binnen een transactie. Als u SET globaal gebruikt op een gepoolde verbinding, kan de tenant_id aan de verbinding blijven "plakken" en lekken naar de volgende gebruiker—een fenomeen dat bekend staat als Pool Contamination.
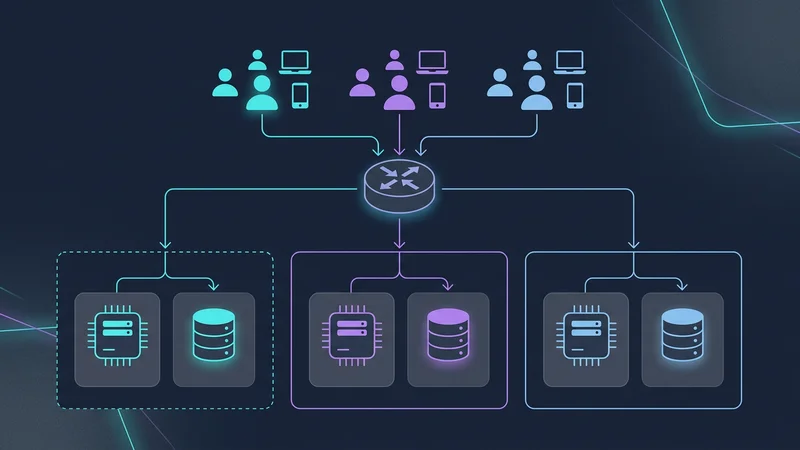
Schaaluitdagingen en het Noisy Neighbor-probleem
Naarmate uw SaaS schaalt, zult u uiteindelijk te maken krijgen met een "Noisy Neighbor"—een enkele tenant wiens verbruik zo hoog piekt dat het andere tenants berooft van resources (CPU, geheugen, I/O).
Cell-Based Architectuur
Om dit te beperken, gebruiken ultra-schaalbare SaaS-applicaties (zoals Slack en Salesforce) een Cell-Based architectuur. In plaats van één gigantische database voor 1.000.000 tenants, maakt u "cells". Elke cell is een zelfstandige eenheid (bijv. een databasecluster + compute) die 50.000 tenants host.
- Blast Radius: Als Cell A uitvalt, wordt slechts 5% van uw klanten getroffen.
- Wereldwijde Expansie: U kunt Cell B in de EU plaatsen en Cell C in de VS om te voldoen aan wetgeving over datasoevereiniteit.
Distributed SQL voor Wereldwijde SaaS
Voor applicaties die één logische wereldwijde database vereisen, zijn Distributed SQL-engines zoals CockroachDB v25.4 de voorkeurskeuze. Hiermee kunt u specifieke rijen "pinnen" aan geografische regio's met behulp van een regional_by_row strategie, wat zorgt voor een lage latentie voor gebruikers terwijl de wereldwijde consistentie behouden blijft.
Schema Migratie en Onderhoud Best Practices
Het beheren van migraties voor 10.000 afzonderlijke tenant-schema's is een onmogelijke handmatige taak. Automatisering via Infrastructure-as-Code (IaC) is de enige weg vooruit.
Automatisering van Multi-Tenant Migraties
Moderne toolkits zoals drizzle-multitenant of aangepaste Terraform providers stellen u in staat om uw databaseschema's als code te behandelen. Wanneer u uw "Template Schema" bijwerkt, loopt de CI/CD-pijplijn door alle tenant-databases en past de wijzigingen toe.
# Voorbeeld: Migraties uitvoeren over alle tenant-schema's
npx drizzle-kit push:pg --config=./drizzle.config.ts --all-tenantsBelangrijke Valkuilen om te Vermijden:
- Willekeurige UUID's: Zoals vermeld, vermijd UUIDv4 voor primaire sleutels. Gebruik UUIDv7.
- Connection Exhaustion: Schalen naar 5.000 tenants met afzonderlijke verbindingen zal uw DB laten crashen. Gebruik een tenant-aware connection pooler zoals Supabase Supavisor of PgBouncer.
- Ontbrekende Indexen op Tenant-kolommen: In een gedeeld schema moet elke index
tenant_idals eerste of tweede kolom bevatten om ervoor te zorgen dat de query optimizer gegevens efficiënt kan filteren.
Veelgestelde Vragen
Wat is het verschil tussen silo-, bridge- en pool-databasemodellen?
Het Silo-model biedt elke tenant een toegewezen database-instantie, wat maximale isolatie biedt maar hogere beheerkosten met zich meebrengt. Het Bridge-model gebruikt een gedeelde database-instantie met aparte schema's voor elke tenant, wat een balans biedt tussen isolatie en kosten. Het Pool-model gebruikt een gedeeld schema waarin alle tenant-gegevens in dezelfde tabellen staan, gescheiden door een tenant-ID, wat de hoogste kostenefficiëntie biedt maar ook het meeste risico.
Hoe waarborg je data-isolatie in een gedeelde multi-tenant database?
Data-isolatie wordt primair gewaarborgd via Row-Level Security (RLS) op databaseniveau, wat de toegang beperkt op basis van de sessiecontext van de gebruiker. Daarnaast moet middleware op applicatieniveau strikt de tenant-resolutie afdwingen door de juiste tenant_id in elke query of sessievariabele te injecteren. Het gebruik van tijdgeordende identifiers zoals UUIDv7 helpt ook om de prestaties en organisatie binnen gedeelde indexen te behouden.
Welke database-architectuur is het beste voor een schalende SaaS-applicatie?
Voor SaaS in een vroeg stadium is het Pool-model met RLS meestal het beste vanwege de lage kosten en eenvoud. Naarmate u schaalt naar enterprise-klanten, heeft een Hybride of Cell-Based architectuur de voorkeur, waarbij de meeste gebruikers in een gedeelde pool blijven terwijl hoogwaardige enterprise-klanten worden gemigreerd naar toegewezen silo's voor betere prestaties en compliance.
Hoe ga je om met schema-migraties voor duizenden tenants?
Schema-migraties moeten worden afgehandeld met Infrastructure-as-Code (IaC) en geautomatiseerde migratie-scripts die wijzigingen parallel over alle schema's kunnen uitvoeren. Tools zoals Drizzle ORM of gespecialiseerde CI/CD-scripts worden gebruikt om ervoor te zorgen dat migraties idempotent zijn en dat fouten in de migratie van één tenant het volledige implementatieproces niet stoppen.
Kan multi-tenancy de prestaties en latentie van de database beïnvloeden?
Ja, multi-tenancy kan leiden tot het Noisy Neighbor-probleem, waarbij het zware resourceverbruik van één tenant de queries voor anderen vertraagt. Bovendien kan, zonder de juiste indexering op tenant_id en het gebruik van connection poolers, de overhead van het beheren van duizenden tenant-contexten de latentie aanzienlijk verhogen en het risico op connection exhaustion vergroten.
Conclusie
Database-ontwerp voor SaaS in 2025–2026 gaat niet langer alleen over de keuze tussen SQL en NoSQL. Het gaat over het kiezen van een strategie die aansluit bij uw zakelijke doelen.
Als u een consumenten-app met een hoog volume bouwt, biedt het Gedeelde Schema (Pool) model met PostgreSQL 18 en RLS de beste prestaties en kosten. Als u zich richt op de zakelijke markt, biedt het Serverless Silo-model de isolatie en compliance die uw klanten eisen, zonder de historische overhead van het beheren van duizenden servers.
Door te standaardiseren op UUIDv7, Cell-Based architecturen te implementeren voor schaalbaarheid en gebruik te maken van geautomatiseerde migratie-toolkits, kunt u een SaaS-backend bouwen die niet alleen robuust is voor vandaag, maar ook klaar is voor de eisen van het volgende decennium.