Introduction : L'évolution du Multi-Tenant
Dans le paysage en constante évolution du Software-as-a-Service (SaaS), la base de données n'est plus seulement un moteur de stockage — c'est la colonne vertébrale architecturale qui détermine l'évolutivité, la sécurité et les marges bénéficiaires de votre application. À l'aube de 2025 et 2026, l'approche « solution unique » de la conception de bases de données a été remplacée par des modèles sophistiqués qui équilibrent l'isolation des clients (tenants) et l'efficacité opérationnelle.
Les équipes d'ingénierie SaaS modernes s'éloignent des bases de données monolithiques au profit d'architectures plus granulaires et « sensibles aux tenants ». Avec la sortie de PostgreSQL 18 et la maturité des technologies de bases de données serverless, les développeurs disposent désormais d'outils autrefois réservés aux entreprises de l'envergure des FAANG. Que vous construisiez un outil B2B spécialisé ou une plateforme d'entreprise mondiale, choisir le bon modèle de conception de base de données est la décision technique la plus critique que vous prendrez.
Modèles d'architecture de bases de données Multi-Tenant
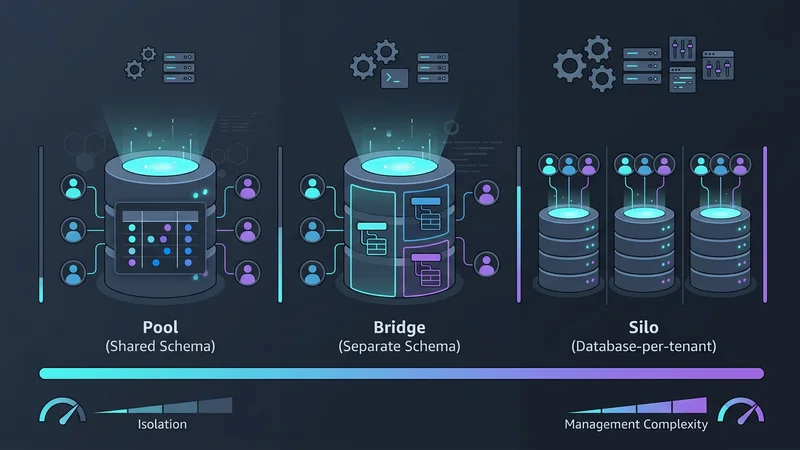
Le choix d'un modèle multi-tenant implique un compromis entre trois facteurs : l'isolation, l'évolutivité et le coût. En 2026, nous les classons en trois modèles principaux : le Pool, le Bridge et le Silo.
Modèle 1 : Base de données partagée, schéma partagé (Le modèle Pool)
Le modèle « Pool » est l'architecture la plus courante pour les applications SaaS à gros volume et à faible coût. Dans ce modèle, tous les tenants partagent la même base de données et les mêmes tables. Les données sont séparées logiquement par une colonne tenant_id dans chaque table.
Avantages :
- Efficacité des coûts : Vous ne payez que pour une seule instance de base de données.
- Agrégation simple : L'exécution d'analyses sur l'ensemble des clients est directe.
- Maintenance : Un seul schéma à migrer, un seul ensemble d'index à gérer.
Inconvénients :
- Effet du « voisin bruyant » (Noisy Neighbor) : Un seul utilisateur intensif peut dégrader les performances pour tous les autres.
- Risque de sécurité : Un bug dans la clause
WHEREde votre application pourrait entraîner une fuite de données.
Modèle 2 : Base de données partagée, schémas séparés (Le modèle Bridge)
Souvent utilisé dans la HealthTech ou la FinTech, le modèle « Bridge » offre un compromis. Chaque tenant dispose de son propre schéma (par exemple, tenant_a.orders, tenant_b.orders) au sein d'une seule instance de base de données physique.
Ce modèle est privilégié en 2025 pour les environnements à forte conformité, comme les applications conformes à la norme HIPAA. Il offre une isolation logique, rendant la fuite de données entre tenants plus difficile, tout en permettant à l'équipe d'infrastructure de gérer un seul cluster de base de données.
Modèle 3 : Une base de données par tenant (Le modèle Silo)
Historiquement, donner à chaque client sa propre base de données était considéré comme un cauchemar opérationnel. Cependant, l'essor des fournisseurs serverless comme Neon et AWS Aurora Serverless v2 a révolutionné cette approche. Ces plateformes permettent des capacités de « mise à l'échelle vers zéro » (scale-to-zero), ce qui signifie que la base de données d'un tenant ne coûte rien lorsqu'elle n'est pas utilisée.
Pourquoi ce modèle gagne en 2026 :
- Zéro fuite : L'isolation physique garantit qu'un tenant ne peut pas accéder aux données d'un autre.
- Personnalisation : Vous pouvez exécuter des migrations ou des versions différentes pour des clients d'entreprise spécifiques.
- Branching : En utilisant le branchement « copy-on-write », vous pouvez intégrer de nouveaux tenants instantanément en clonant une base de données modèle.
Innovations modernes et meilleures pratiques (2025–2026)
La sortie de PostgreSQL 18 a fondamentalement changé la façon dont nous implémentons ces modèles. Deux fonctionnalités se distinguent : les E/S asynchrones natives (AIO) et le support natif de UUIDv7.
Le passage à l'UUIDv7
Pendant des années, les développeurs ont hésité entre les entiers séquentiels (rapides mais peu sûrs) et les UUIDv4 aléatoires (sûrs mais lents pour les index). L'UUIDv7 est le standard de 2026 car il est ordonné dans le temps. Cela évite la fragmentation de l'index B-tree courante avec les UUID aléatoires, maintenant vos insertions rapides même lorsque votre SaaS atteint des milliards de lignes.
Isolation vectorielle dans le SaaS natif de l'IA
Avec l'essor de la génération augmentée par récupération (RAG), les bases de données SaaS stockent désormais des vector embeddings. Le « Modèle d'isolation vectorielle » consiste à utiliser la sécurité au niveau des lignes (RLS) sur les colonnes vectorielles pour s'assurer qu'un agent d'IA ne récupère que le contexte pertinent pour le tenant spécifique, évitant ainsi les « hallucinations de l'IA » impliquant les données d'autres clients.
Stratégies d'isolation des données et de résolution des tenants
L'isolation est le « Saint Graal » du SaaS. En 2026, l'industrie s'est standardisée sur deux méthodes principales pour garantir qu'aucun client ne voie jamais les données d'un autre.
Row-Level Security (RLS) : Le standard absolu
Si vous utilisez le modèle « Pool », la sécurité au niveau des lignes de PostgreSQL est obligatoire. Au lieu d'ajouter manuellement tenant_id à chaque requête, vous définissez une politique au niveau de la base de données.
-- Activer RLS sur la table
ALTER TABLE orders ENABLE ROW LEVEL SECURITY;
-- Créer une politique qui restreint l'accès en fonction d'une variable de session
CREATE POLICY tenant_isolation_policy ON orders
USING (tenant_id = current_setting('app.current_tenant')::uuid);Résolution des tenants via Middleware
Pour que le RLS fonctionne, votre application doit « dire » à la base de données quel tenant est actuellement actif. Dans une stack TypeScript moderne utilisant Drizzle ORM ou Prisma, cela est géré dans le middleware de requête.
// middleware/tenant-resolver.ts
import { NextFunction, Request, Response } from 'express';
import { db } from '../db';
export async function tenantMiddleware(req: Request, res: Response, next: NextFunction) {
const tenantId = req.auth.claims.tenant_id; // Extrait du JWT
if (!tenantId) {
return res.status(401).send('Unauthorized');
}
// Utiliser une transaction pour définir la variable locale pour cette connexion
await db.transaction(async (tx) => {
await tx.execute(sql`SET LOCAL app.current_tenant = ${tenantId}`);
// Stocker l'objet de transaction dans la requête pour l'utiliser dans les contrôleurs
req.tenantDb = tx;
next();
});
}Attention : Utilisez toujours SET LOCAL au sein d'une transaction. Si vous utilisez SET globalement sur une connexion poolée, le tenant_id pourrait « rester » sur la connexion et fuiter vers l'utilisateur suivant — un phénomène connu sous le nom de contamination de pool (Pool Contamination).
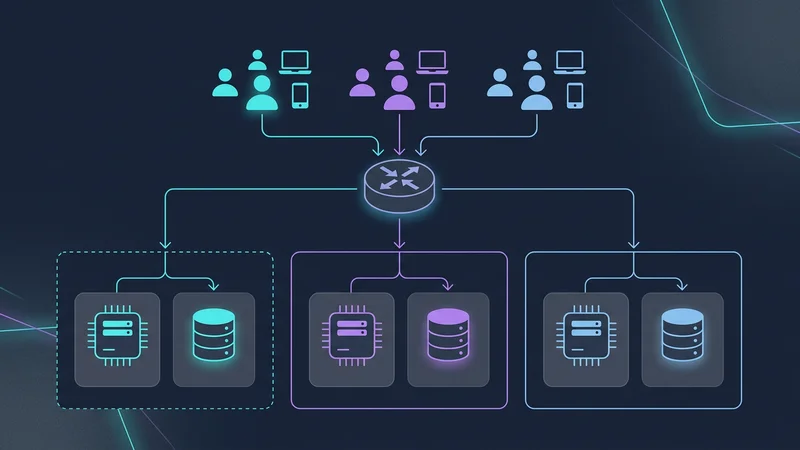
Défis de mise à l'échelle et problème du voisin bruyant
À mesure que votre SaaS se développe, vous rencontrerez inévitablement un « voisin bruyant » — un seul tenant dont l'utilisation grimpe si haut qu'elle prive les autres tenants de ressources (CPU, mémoire, E/S).
Architecture par cellules (Cell-Based Architecture)
Pour atténuer cela, les applications SaaS à ultra-grande échelle (comme Slack et Salesforce) utilisent une architecture par cellules. Au lieu d'une base de données géante pour 1 000 000 de tenants, vous créez des « cellules ». Chaque cellule est une unité autonome (par exemple, un cluster de base de données + calcul) qui héberge 50 000 tenants.
- Rayon d'impact (Blast Radius) : Si la cellule A tombe en panne, seulement 5 % de vos clients sont affectés.
- Expansion mondiale : Vous pouvez placer la cellule B en UE et la cellule C aux États-Unis pour satisfaire aux lois sur la résidence des données.
SQL distribué pour le SaaS mondial
Pour les applications nécessitant une base de données logique unique et mondiale, les moteurs SQL distribués comme CockroachDB v25.4 sont le choix privilégié. Ils vous permettent d'« épingler » des lignes spécifiques à des régions géographiques en utilisant une stratégie regional_by_row, garantissant une faible latence pour les utilisateurs tout en maintenant une cohérence globale.
Meilleures pratiques pour la migration et la maintenance des schémas
Gérer les migrations pour 10 000 schémas de tenants distincts est une tâche manuelle impossible. L'automatisation via l'Infrastructure-as-Code (IaC) est la seule voie possible.
Automatisation des migrations multi-tenant
Des boîtes à outils modernes comme drizzle-multitenant ou des fournisseurs Terraform personnalisés vous permettent de traiter vos schémas de base de données comme du code. Lorsque vous mettez à jour votre « Schéma Modèle », le pipeline CI/CD itère sur toutes les bases de données des tenants et applique les modifications.
# Exemple : Exécution des migrations sur tous les schémas de tenants
npx drizzle-kit push:pg --config=./drizzle.config.ts --all-tenantsPièges clés à éviter :
- UUID aléatoires : Comme mentionné, évitez l'UUIDv4 pour les clés primaires. Utilisez l'UUIDv7.
- Épuisement des connexions : Passer à 5 000 tenants avec des connexions séparées fera planter votre base de données. Utilisez un gestionnaire de pool de connexions sensible aux tenants comme Supabase Supavisor ou PgBouncer.
- Index manquants sur les colonnes de tenants : Dans un schéma partagé, chaque index doit inclure
tenant_idcomme première ou deuxième colonne pour garantir que l'optimiseur de requête puisse filtrer les données efficacement.
Foire aux questions
Quelle est la différence entre les modèles de base de données silo, bridge et pool ?
Le modèle Silo fournit à chaque tenant une instance de base de données dédiée, offrant une isolation maximale mais une charge de gestion plus élevée. Le modèle Bridge utilise une instance de base de données partagée avec des schémas distincts pour chaque tenant, équilibrant isolation et coût. Le modèle Pool utilise un schéma partagé où toutes les données des tenants résident dans les mêmes tables, séparées par un ID de tenant, offrant l'efficacité de coût la plus élevée mais le risque le plus grand.
Comment assurer l'isolation des données dans une base de données multi-tenant partagée ?
L'isolation des données est principalement assurée par la sécurité au niveau des lignes (RLS) au niveau de la base de données, qui restreint l'accès en fonction du contexte de session de l'utilisateur. De plus, le middleware au niveau de l'application doit strictement imposer la résolution du tenant en injectant le bon tenant_id dans chaque requête ou variable de session. L'utilisation d'identifiants ordonnés dans le temps comme UUIDv7 aide également à maintenir la performance au sein des index partagés.
Quelle architecture de base de données est la meilleure pour une application SaaS en pleine croissance ?
Pour un SaaS en phase de démarrage, le modèle Pool avec RLS est généralement préférable en raison de son faible coût et de sa simplicité. À mesure que vous évoluez vers des clients d'entreprise, une architecture hybride ou par cellules est privilégiée, où la plupart des utilisateurs restent dans un pool partagé tandis que les clients d'entreprise à haute valeur sont migrés vers des silos dédiés pour de meilleures performances et une meilleure conformité.
Comment gérer les migrations de schémas pour des milliers de tenants ?
Les migrations de schémas doivent être gérées à l'aide de l'Infrastructure-as-Code (IaC) et d'exécuteurs de migration automatisés capables d'exécuter les changements en parallèle sur tous les schémas. Des outils comme Drizzle ORM ou des scripts CI/CD spécialisés sont utilisés pour s'assurer que les migrations sont idempotentes et que les échecs dans la migration d'un tenant n'arrêtent pas l'ensemble du processus de déploiement.
Le multi-tenant peut-il affecter les performances et la latence de la base de données ?
Oui, le multi-tenant peut entraîner le problème du voisin bruyant, où l'utilisation intensive des ressources par un tenant ralentit les requêtes pour les autres. De plus, sans une indexation appropriée sur tenant_id et l'utilisation de gestionnaires de pool de connexions, la surcharge liée à la gestion de milliers de contextes de tenants peut augmenter considérablement la latence et risquer l'épuisement des connexions.
Conclusion
La conception de bases de données pour le SaaS en 2025–2026 ne consiste plus seulement à choisir entre SQL et NoSQL. Il s'agit de choisir une stratégie qui s'aligne sur vos objectifs commerciaux.
Si vous construisez une application grand public à gros volume, le modèle à schéma partagé (Pool) avec PostgreSQL 18 et RLS offre les meilleures performances et le meilleur coût. Si vous ciblez le marché des entreprises, le modèle Silo serverless offre l'isolation et la conformité exigées par vos clients sans la charge historique de gestion de milliers de serveurs.
En vous standardisant sur l'UUIDv7, en implémentant des architectures par cellules pour l'échelle et en exploitant des boîtes à outils de migration automatisées, vous pouvez construire un backend SaaS non seulement robuste aujourd'hui, mais prêt pour les exigences de la prochaine décennie.