Introducción: La Evolución del Multi-Tenant
En el panorama de rápida evolución del Software-as-a-Service (SaaS), la base de datos ya no es solo un motor de almacenamiento; es la columna vertebral arquitectónica que determina la escalabilidad, la seguridad y los márgenes de beneficio de tu aplicación. A medida que avanzamos por 2025 y hacia 2026, el enfoque de "talla única" para el diseño de bases de datos ha sido reemplazado por patrones sofisticados que equilibran el aislamiento de los inquilinos (tenants) con la eficiencia operativa.
Los equipos modernos de ingeniería SaaS se están alejando de las bases de datos monolíticas hacia arquitecturas más granulares y "conscientes del inquilino". Con el lanzamiento de PostgreSQL 18 y la maduración de las tecnologías de bases de datos serverless, los desarrolladores ahora tienen herramientas que antes estaban reservadas para empresas a escala FAANG. Ya sea que estés construyendo una herramienta B2B boutique o una plataforma empresarial global, elegir el patrón de diseño de base de datos correcto es la decisión técnica más crítica que tomarás.
Patrones de Arquitectura de Bases de Datos Multi-Tenant
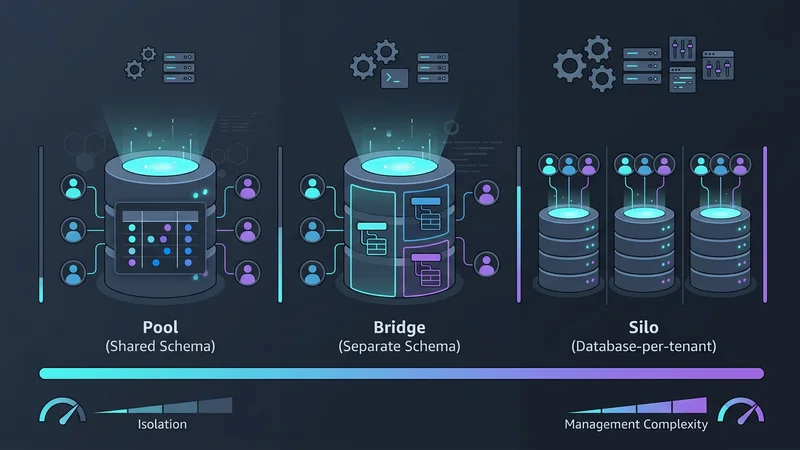
Elegir un modelo de multi-tenancy implica un compromiso entre tres factores: Aislamiento, Escalabilidad y Coste. En 2026, categorizamos estos en tres patrones principales: el Pool, el Bridge y el Silo.
Patrón 1: Base de Datos Compartida, Esquema Compartido (El Modelo Pool)
El modelo "Pool" es la arquitectura más común para aplicaciones SaaS de alto volumen y bajo coste. En este patrón, todos los inquilinos comparten la misma base de datos y las mismas tablas. Los datos se separan lógicamente mediante una columna tenant_id en cada tabla.
Pros:
- Eficiencia de Costes: Solo pagas por una instancia de base de datos.
- Agregación Sencilla: Realizar analíticas de todos los clientes es directo.
- Mantenimiento: Un solo esquema que migrar, un solo conjunto de índices que gestionar.
Cons:
- Efecto del Vecino Ruidoso (Noisy Neighbor): Un solo usuario con mucha carga puede degradar el rendimiento para todos.
- Riesgo de Seguridad: Un error en la cláusula
WHEREde tu aplicación podría provocar una filtración de datos.
Patrón 2: Base de Datos Compartida, Esquemas Separados (El Modelo Bridge)
Utilizado a menudo en HealthTech o FinTech, el modelo "Bridge" proporciona un punto medio. Cada inquilino obtiene su propio esquema (por ejemplo, tenant_a.orders, tenant_b.orders) dentro de una única instancia física de base de datos.
Este modelo es favorecido en 2025 para entornos con alta carga de cumplimiento normativo, como las aplicaciones que cumplen con HIPAA. Proporciona una separación lógica, dificultando la filtración de datos entre inquilinos, mientras permite al equipo de infraestructura gestionar un solo clúster de base de datos.
Patrón 3: Base de Datos por Inquilino (El Modelo Silo)
Históricamente, dar a cada cliente su propia base de datos se consideraba una pesadilla operativa. Sin embargo, el auge de proveedores serverless como Neon y AWS Aurora Serverless v2 ha revolucionado esto. Estas plataformas permiten capacidades de "escala a cero" (scale-to-zero), lo que significa que la base de datos de un inquilino no cuesta nada cuando no se está utilizando.
Por qué está ganando en 2026:
- Cero Filtraciones: La separación física garantiza que un inquilino no pueda acceder a los datos de otro.
- Personalización: Puedes ejecutar diferentes migraciones o versiones para clientes corporativos específicos.
- Ramificación (Branching): Utilizando la ramificación "copy-on-write", puedes dar de alta a nuevos inquilinos instantáneamente clonando una base de datos de plantilla.
Innovaciones Modernas y Mejores Prácticas (2025–2026)
El lanzamiento de PostgreSQL 18 ha cambiado fundamentalmente la forma en que implementamos estos patrones. Destacan dos características: I/O Asíncrono Nativo (AIO) y soporte nativo para UUIDv7.
El Cambio a UUIDv7
Durante años, los desarrolladores debatieron entre enteros secuenciales (rápidos pero inseguros) y UUIDv4 aleatorios (seguros pero lentos para los índices). UUIDv7 es el estándar de 2026 porque está ordenado por tiempo. Esto evita la fragmentación del índice B-tree común con los UUID aleatorios, manteniendo tus inserciones rápidas incluso cuando tu SaaS crece a miles de millones de filas.
Aislamiento de Vectores en SaaS Nativo de IA
Con el auge de la Generación Aumentada por Recuperación (RAG), las bases de datos SaaS ahora almacenan embeddings de vectores. El "Patrón de Aislamiento de Vectores" consiste en utilizar Row-Level Security (RLS) en las columnas de vectores para garantizar que un agente de IA solo recupere el contexto relevante para el inquilino específico, evitando "Alucinaciones de IA" que involucren datos de otros clientes.
Estrategias de Aislamiento de Datos y Resolución de Inquilinos
El aislamiento es el "santo grial" del SaaS. En 2026, la industria se ha estandarizado en dos métodos principales para garantizar que ningún cliente vea nunca los datos de otro.
Row-Level Security (RLS): El Estándar de Oro
Si estás utilizando el modelo "Pool", el Row-Level Security de PostgreSQL es obligatorio. En lugar de añadir manualmente el tenant_id a cada consulta, defines una política a nivel de base de datos.
-- Enable RLS on the table
ALTER TABLE orders ENABLE ROW LEVEL SECURITY;
-- Create a policy that restricts access based on a session variable
CREATE POLICY tenant_isolation_policy ON orders
USING (tenant_id = current_setting('app.current_tenant')::uuid);Resolución de Inquilinos mediante Middleware
Para que RLS funcione, tu aplicación debe "decirle" a la base de datos qué inquilino está activo actualmente. En un stack moderno de TypeScript utilizando Drizzle ORM o Prisma, esto se gestiona en el middleware de la solicitud.
// middleware/tenant-resolver.ts
import { NextFunction, Request, Response } from 'express';
import { db } from '../db';
export async function tenantMiddleware(req: Request, res: Response, next: NextFunction) {
const tenantId = req.auth.claims.tenant_id; // Extracted from JWT
if (!tenantId) {
return res.status(401).send('Unauthorized');
}
// Use a transaction to set the local variable for this connection
await db.transaction(async (tx) => {
await tx.execute(sql`SET LOCAL app.current_tenant = ${tenantId}`);
// Store the transaction object in the request for use in controllers
req.tenantDb = tx;
next();
});
}Advertencia: Utiliza siempre SET LOCAL dentro de una transacción. Si utilizas SET de forma global en una conexión agrupada (pooled), el tenant_id podría "pegarse" a la conexión y filtrarse al siguiente usuario, un fenómeno conocido como Contaminación del Pool.
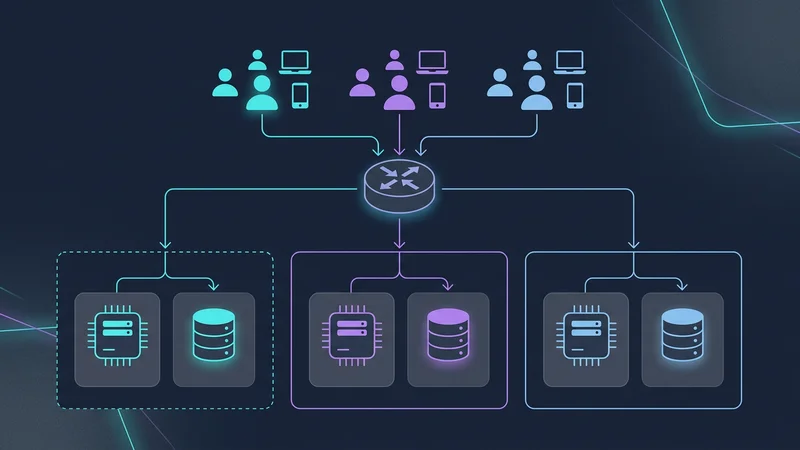
Desafíos de Escalabilidad y el Problema del Vecino Ruidoso
A medida que tu SaaS escala, eventualmente te encontrarás con un "Vecino Ruidoso": un solo inquilino cuyo uso aumenta tanto que priva a otros inquilinos de recursos (CPU, Memoria, I/O).
Arquitectura Basada en Celdas
Para mitigar esto, las aplicaciones SaaS de ultra-escala (como Slack y Salesforce) utilizan la Arquitectura Basada en Celdas. En lugar de una base de datos gigante para 1,000,000 de inquilinos, creas "celdas". Cada celda es una unidad autónoma (por ejemplo, un clúster de base de datos + cómputo) que aloja a 50,000 inquilinos.
- Radio de Explosión: Si la Celda A cae, solo el 5% de tus clientes se ven afectados.
- Expansión Global: Puedes ubicar la Celda B en la UE y la Celda C en EE. UU. para cumplir con las leyes de residencia de datos.
SQL Distribuido para SaaS Global
Para aplicaciones que requieren una única base de datos lógica global, los motores de SQL Distribuido como CockroachDB v25.4 son la opción preferida. Permiten "anclar" filas específicas a regiones geográficas utilizando una estrategia regional_by_row, garantizando una baja latencia para los usuarios mientras se mantiene la consistencia global.
Mejores Prácticas para la Migración de Esquemas y el Mantenimiento
Gestionar migraciones para 10,000 esquemas de inquilinos separados es una tarea manual imposible. La automatización mediante Infraestructura como Código (IaC) es el único camino a seguir.
Automatización de Migraciones Multi-Tenant
Los toolkits modernos como drizzle-multitenant o los proveedores personalizados de Terraform te permiten tratar tus esquemas de base de datos como código. Cuando actualizas tu "Esquema de Plantilla", el pipeline de CI/CD itera a través de todas las bases de datos de los inquilinos y aplica los cambios.
# Ejemplo: Ejecución de migraciones en todos los esquemas de inquilinos
npx drizzle-kit push:pg --config=./drizzle.config.ts --all-tenantsEscollos Clave a Evitar:
- UUIDs Aleatorios: Como se mencionó, evita UUIDv4 para claves primarias. Usa UUIDv7.
- Agotamiento de Conexiones: Escalar a 5,000 inquilinos con conexiones separadas colapsará tu base de datos. Utiliza un pooler de conexiones consciente del inquilino como Supabase Supavisor o PgBouncer.
- Falta de Índices en Columnas de Inquilino: En un esquema compartido, cada índice debe incluir
tenant_idcomo la primera o segunda columna para asegurar que el optimizador de consultas pueda filtrar los datos de manera eficiente.
Preguntas Frecuentes
¿Cuál es la diferencia entre los modelos de base de datos silo, bridge y pool?
El modelo Silo proporciona a cada inquilino una instancia de base de datos dedicada, ofreciendo el máximo aislamiento pero una mayor carga de gestión. El modelo Bridge utiliza una instancia de base de datos compartida con esquemas separados para cada inquilino, equilibrando el aislamiento y el coste. El modelo Pool utiliza un esquema compartido donde todos los datos de los inquilinos residen en las mismas tablas, separados por un ID de inquilino, ofreciendo la mayor eficiencia de costes pero el mayor riesgo.
¿Cómo se garantiza el aislamiento de datos en una base de datos multi-tenant compartida?
El aislamiento de datos se garantiza principalmente a través de Row-Level Security (RLS) a nivel de base de datos, que restringe el acceso basado en el contexto de la sesión del usuario. Además, el middleware a nivel de aplicación debe aplicar estrictamente la resolución del inquilino inyectando el tenant_id correcto en cada consulta o variable de sesión. El uso de identificadores ordenados por tiempo como UUIDv7 también ayuda a mantener el rendimiento y la organización dentro de los índices compartidos.
¿Qué arquitectura de base de datos es mejor para una aplicación SaaS en crecimiento?
Para un SaaS en etapa inicial, el modelo Pool con RLS suele ser el mejor debido a su bajo coste y simplicidad. A medida que escalas hacia clientes corporativos, se prefiere una arquitectura Híbrida o Basada en Celdas, donde la mayoría de los usuarios permanecen en un pool compartido mientras que los clientes corporativos de alto valor se migran a silos dedicados para un mejor rendimiento y cumplimiento.
¿Cómo se gestionan las migraciones de esquemas para miles de inquilinos?
Las migraciones de esquemas deben gestionarse utilizando Infraestructura como Código (IaC) y ejecutores de migración automatizados que puedan ejecutar cambios en paralelo en todos los esquemas. Se utilizan herramientas como Drizzle ORM o scripts especializados de CI/CD para garantizar que las migraciones sean idempotentes y que los fallos en la migración de un inquilino no detengan todo el proceso de despliegue.
¿Puede el multi-tenancy afectar el rendimiento y la latencia de la base de datos?
Sí, el multi-tenancy puede llevar al problema del Vecino Ruidoso, donde el uso intensivo de recursos por parte de un inquilino ralentiza las consultas para otros. Además, sin una indexación adecuada en tenant_id y el uso de poolers de conexiones, la sobrecarga de gestionar miles de contextos de inquilinos puede aumentar significativamente la latencia y arriesgar el agotamiento de las conexiones.
Conclusión
El diseño de bases de datos para SaaS en 2025–2026 ya no se trata solo de elegir entre SQL y NoSQL. Se trata de elegir una estrategia que se alinee con tus objetivos de negocio.
Si estás construyendo una aplicación de consumo de alto volumen, el modelo de Esquema Compartido (Pool) con PostgreSQL 18 y RLS ofrece el mejor rendimiento y coste. Si te diriges al mercado corporativo, el modelo de Silo Serverless proporciona el aislamiento y el cumplimiento que tus clientes exigen sin la carga histórica de gestionar miles de servidores.
Al estandarizar con UUIDv7, implementar Arquitecturas Basadas en Celdas para la escala y aprovechar los toolkits de migración automatizados, puedes construir un backend SaaS que no solo sea robusto hoy, sino que esté listo para las demandas de la próxima década.