Úvod: Evoluce Multi-Tenancy
V rychle se vyvíjejícím světě Software-as-a-Service (SaaS) již databáze není jen pouhým úložištěm – je to architektonická páteř, která určuje škálovatelnost, bezpečnost a ziskové marže vaší aplikace. Jak postupujeme rokem 2025 do roku 2026, přístup „one-size-fits-all“ k návrhu databází byl nahrazen sofistikovanými vzory, které vyvažují izolaci tenantů (klientů) s provozní efektivitou.
Moderní SaaS inženýrské týmy ustupují od monolitických databází směrem k granulárnějším architekturám, které „vnímají tenanty“ (tenant-aware). S vydáním PostgreSQL 18 a dozráním serverless databázových technologií mají nyní vývojáři k dispozici nástroje, které byly dříve vyhrazeny pouze pro podniky velikosti FAANG. Ať už stavíte butikový B2B nástroj nebo globální podnikovou platformu, výběr správného návrhového vzoru databáze je tím nejkritičtějším technickým rozhodnutím, které učiníte.
Architektonické vzory multi-tenant databází
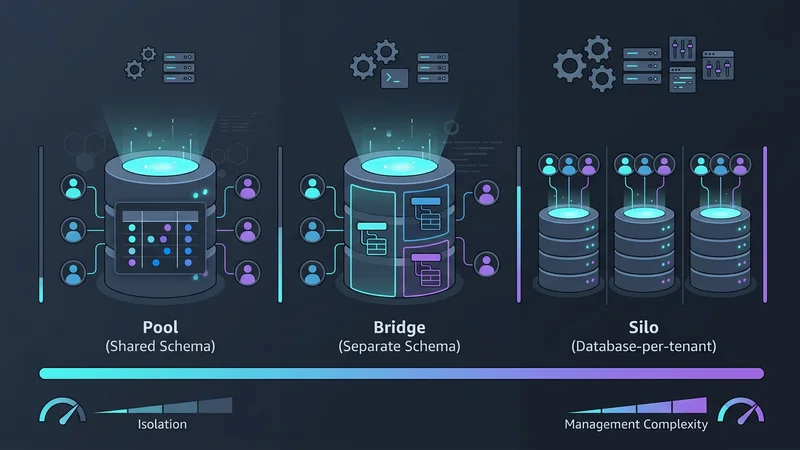
Výběr multi-tenancy modelu zahrnuje kompromis mezi třemi faktory: izolací, škálovatelností a náklady. V roce 2026 tyto modely kategorizujeme do tří primárních vzorů: Pool, Bridge a Silo.
Vzor 1: Sdílená databáze, sdílené schéma (Model Pool)
Model „Pool“ je nejběžnější architekturou pro vysokoobjemové a nízkonákladové SaaS aplikace. V tomto vzoru všichni tenanti sdílejí stejnou databázi a stejné tabulky. Data jsou logicky oddělena sloupcem tenant_id v každé tabulce.
Plusy:
- Nákladová efektivita: Platíte pouze za jednu instanci databáze.
- Jednoduchá agregace: Provádění analýz napříč všemi zákazníky je přímočaré.
- Údržba: Jedno schéma pro migraci, jedna sada indexů pro správu.
Mínusy:
- Efekt hlučného souseda (Noisy Neighbor): Jeden extrémně aktivní uživatel může zhoršit výkon pro všechny ostatní.
- Bezpečnostní riziko: Chyba v klauzuli
WHEREvaší aplikace by mohla vést k úniku dat.
Vzor 2: Sdílená databáze, oddělená schémata (Model Bridge)
Často používaný v HealthTech nebo FinTech, model „Bridge“ poskytuje zlatou střední cestu. Každý tenant získá své vlastní schéma (např. tenant_a.orders, tenant_b.orders) v rámci jedné fyzické instance databáze.
Tento model je v roce 2025 upřednostňován v prostředích s vysokými nároky na shodu s předpisy (compliance), jako jsou aplikace vyhovující HIPAA. Poskytuje logické oddělení, které ztěžuje únik dat mezi tenanty, zatímco infrastrukturnímu týmu stále umožňuje spravovat jediný databázový cluster.
Vzor 3: Databáze pro každého tenanta (Model Silo)
Historicky bylo poskytování vlastní databáze každému zákazníkovi považováno za provozní noční můru. Vzestup serverless poskytovatelů jako Neon a AWS Aurora Serverless v2 to však od základů změnil. Tyto platformy umožňují schopnosti „scale-to-zero“, což znamená, že databáze tenanta nestojí nic, když se nepoužívá.
Proč v roce 2026 vyhrává:
- Nulový únik dat: Fyzické oddělení zajišťuje, že jeden tenant nemůže přistupovat k datům jiného.
- Customizace: Můžete spouštět různé migrace nebo verze pro konkrétní firemní klienty.
- Branching: Pomocí branchingu typu „copy-on-write“ můžete okamžitě onboardovat nové tenanty klonováním šablonové databáze.
Moderní inovace a osvědčené postupy (2025–2026)
Vydání PostgreSQL 18 zásadně změnilo způsob, jakým tyto vzory implementujeme. Vyčnívají dvě funkce: nativní asynchronní I/O (AIO) a nativní podpora UUIDv7.
Přechod na UUIDv7
Po léta vývojáři debatovali mezi sekvenčními celými čísly (rychlá, ale nebezpečná) a náhodnými UUIDv4 (bezpečná, ale pomalá pro indexy). UUIDv7 je standardem pro rok 2026, protože je časově seřazené. To zabraňuje fragmentaci B-tree indexů, která je běžná u náhodných UUID, a udržuje vaše vkládání (inserts) rychlé, i když vaše SaaS aplikace vyroste na miliardy řádků.
Vektorová izolace v AI-Native SaaS
S nárůstem Retrieval-Augmented Generation (RAG) nyní SaaS databáze ukládají vektorové embeddingy. „Vzor vektorové izolace“ (Vector Isolation Pattern) zahrnuje použití Row-Level Security (RLS) na vektorových sloupcích, aby bylo zajištěno, že AI agent získá pouze kontext relevantní pro konkrétního tenanta, čímž se zabrání „AI halucinacím“ zahrnujícím data jiných zákazníků.
Izolace dat a strategie rozlišení tenantů
Izolace je „svatým grálem“ SaaS. V roce 2026 se průmysl standardizoval na dvou primárních metodách zajištění toho, aby žádný zákazník nikdy neviděl data jiného.
Row-Level Security (RLS): Zlatý standard
Pokud používáte model „Pool“, je Row-Level Security v PostgreSQL povinností. Místo ručního přidávání tenant_id ke každému dotazu definujete politiku na úrovni databáze.
-- Enable RLS on the table
ALTER TABLE orders ENABLE ROW LEVEL SECURITY;
-- Create a policy that restricts access based on a session variable
CREATE POLICY tenant_isolation_policy ON orders
USING (tenant_id = current_setting('app.current_tenant')::uuid);Rozlišení tenanta přes Middleware
Aby RLS fungovalo, vaše aplikace musí databázi „říct“, který tenant je aktuálně aktivní. V moderním TypeScript stacku používajícím Drizzle ORM nebo Prisma se toto řeší v middleware požadavku.
// middleware/tenant-resolver.ts
import { NextFunction, Request, Response } from 'express';
import { db } from '../db';
export async function tenantMiddleware(req: Request, res: Response, next: NextFunction) {
const tenantId = req.auth.claims.tenant_id; // Extracted from JWT
if (!tenantId) {
return res.status(401).send('Unauthorized');
}
// Use a transaction to set the local variable for this connection
await db.transaction(async (tx) => {
await tx.execute(sql`SET LOCAL app.current_tenant = ${tenantId}`);
// Store the transaction object in the request for use in controllers
req.tenantDb = tx;
next();
});
}Varování: Vždy používejte SET LOCAL v rámci transakce. Pokud použijete SET globálně na poolovaném spojení, tenant_id by mohlo na spojení „ulpět“ a uniknout k dalšímu uživateli – jev známý jako kontaminace poolu (Pool Contamination).
Problémy se škálováním a problém hlučného souseda
Jak vaše SaaS aplikace škáluje, nakonec narazíte na „hlučného souseda“ – jednoho tenanta, jehož využití vyskočí tak vysoko, že ostatní tenanty připraví o zdroje (CPU, paměť, I/O).
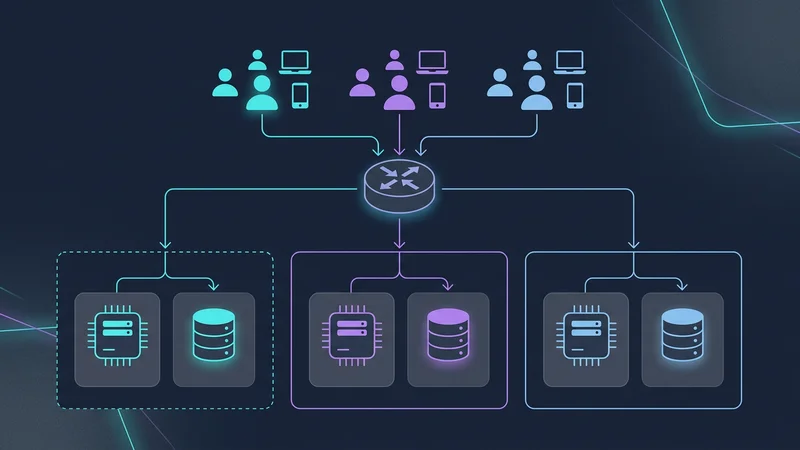
Buňková architektura (Cell-Based Architecture)
Ke zmírnění tohoto problému používají ultra-škálovatelné SaaS aplikace (jako Slack a Salesforce) buňkovou architekturu. Místo jedné obří databáze pro 1 000 000 tenantů vytvoříte „buňky“. Každá buňka je samostatná jednotka (např. databázový cluster + compute), která hostuje 50 000 tenantů.
- Dosah dopadu (Blast Radius): Pokud buňka A vypadne, ovlivní to pouze 5 % vašich zákazníků.
- Globální expanze: Buňku B můžete umístit v EU a buňku C v USA, abyste vyhověli zákonům o uchovávání dat.
Distribuované SQL pro globální SaaS
Pro aplikace vyžadující jedinou logickou globální databázi jsou preferovanou volbou distribuované SQL stroje jako CockroachDB v25.4. Umožňují vám „připnout“ konkrétní řádky ke geografickým regionům pomocí strategie regional_by_row, což zajišťuje nízkou latenci pro uživatele při zachování globální konzistence.
 Architecture), kde jsou různé skupiny tenantů směrovány do samostatných databázových „buněk“, aby se předešlo problémům s hlučnými sousedy a omezil se dosah dopadu">
Architecture), kde jsou různé skupiny tenantů směrovány do samostatných databázových „buněk“, aby se předešlo problémům s hlučnými sousedy a omezil se dosah dopadu">
Osvědčené postupy pro migraci schémat a údržbu
Správa migrací pro 10 000 samostatných schémat tenantů je nemožný manuální úkol. Automatizace prostřednictvím Infrastructure-as-Code (IaC) je jedinou cestou vpřed.
Automatizace multi-tenant migrací
Moderní sady nástrojů jako drizzle-multitenant nebo vlastní Terraform provideři vám umožňují zacházet s databázovými schématy jako s kódem. Když aktualizujete své „šablonové schéma“, CI/CD pipeline projde všechny databáze tenantů a aplikuje změny.
# Example: Running migrations across all tenant schemas
npx drizzle-kit push:pg --config=./drizzle.config.ts --all-tenantsKlíčové chyby, kterým je třeba se vyhnout:
- Náhodná UUID: Jak již bylo zmíněno, vyhněte se UUIDv4 pro primární klíče. Používejte UUIDv7.
- Vyčerpání spojení (Connection Exhaustion): Škálování na 5 000 tenantů s oddělenými spojeními shodí vaši DB. Použijte tenant-aware connection pooler jako Supabase Supavisor nebo PgBouncer.
- Chybějící indexy na sloupcích tenanta: Ve sdíleném schématu musí každý jednotlivý index zahrnovat
tenant_idjako první nebo druhý sloupec, aby optimalizátor dotazů mohl efektivně filtrovat data.
Často kladené otázky
Jaký je rozdíl mezi modely databází silo, bridge a pool?
Model Silo poskytuje každému tenantovi vyhrazenou instanci databáze, což nabízí maximální izolaci, ale vyšší režii na správu. Model Bridge využívá sdílenou instanci databáze s oddělenými schématy pro každého tenanta, čímž vyvažuje izolaci a náklady. Model Pool využívá sdílené schéma, kde data všech tenantů sídlí ve stejných tabulkách, oddělená ID tenanta, což nabízí nejvyšší nákladovou efektivitu, ale největší riziko.
Jak zajistíte izolaci dat ve sdílené multi-tenant databázi?
Izolace dat je primárně zajištěna prostřednictvím Row-Level Security (RLS) na úrovni databáze, která omezuje přístup na základě kontextu relace uživatele. Kromě toho musí middleware na úrovni aplikace striktně vynucovat rozlišení tenanta vložením správného tenant_id do každého dotazu nebo proměnné relace. Používání časově seřazených identifikátorů jako UUIDv7 také pomáhá udržovat výkon a organizaci v rámci sdílených indexů.
Která databázová architektura je nejlepší pro škálující se SaaS aplikaci?
Pro SaaS v rané fázi je obvykle nejlepší model Pool s RLS kvůli nízkým nákladům a jednoduchosti. Jak škálujete směrem k podnikovým zákazníkům, preferuje se hybridní nebo buňková architektura, kde většina uživatelů zůstává ve sdíleném poolu, zatímco vysoce hodnotní firemní klienti jsou migrováni do vyhrazených sil pro lepší výkon a compliance.
Jak řešíte migrace schémat pro tisíce tenantů?
Migrace schémat by měly být řešeny pomocí Infrastructure-as-Code (IaC) a automatizovaných migračních nástrojů, které dokážou provádět změny paralelně napříč všemi schématy. Nástroje jako Drizzle ORM nebo specializované CI/CD skripty se používají k zajištění toho, aby migrace byly idempotentní a aby selhání migrace u jednoho tenanta nezastavilo celý proces nasazení.
Může multi-tenancy ovlivnit výkon a latenci databáze?
Ano, multi-tenancy může vést k problému hlučného souseda, kdy intenzivní využívání zdrojů jedním tenantem zpomaluje dotazy ostatních. Navíc bez řádného indexování tenant_id a použití connection poolerů může režie správy tisíců kontextů tenantů výrazně zvýšit latenci a riziko vyčerpání spojení.
Závěr
Návrh databází pro SaaS v letech 2025–2026 už není jen o výběru mezi SQL a NoSQL. Je to o volbě strategie, která je v souladu s vašimi obchodními cíli.
Pokud stavíte spotřebitelskou aplikaci s vysokým objemem dat, model sdíleného schématu (Pool) s PostgreSQL 18 a RLS nabízí nejlepší výkon a náklady. Pokud cílíte na podnikový trh, serverless model Silo poskytuje izolaci a compliance, kterou vaši zákazníci vyžadují, bez historické režie spojené se správou tisíců serverů.
Standardizací na UUIDv7, implementací buňkových architektur pro škálování a využitím automatizovaných sad nástrojů pro migraci můžete vybudovat SaaS backend, který je nejen robustní dnes, ale připravený i na požadavky příštího desetiletí.