Introduktion: Den flersidiga (multi-tenant) evolutionen
I det snabbt föränderliga landskapet för Software-as-a-Service (SaaS) är databasen inte längre bara en lagringsmotor – den är den arkitektoniska ryggraden som avgör din applikations skalbarhet, säkerhet och vinstmarginaler. När vi rör oss genom 2025 och in i 2026 har "en lösning för alla"-metoden för databasdesign ersatts av sofistikerade mönster som balanserar isolering mellan hyresgäster (tenants) med operativ effektivitet.
Moderna SaaS-utvecklingsteam rör sig bort från monolitiska databaser mot mer granulära, "tenant-aware" arkitekturer. Med lanseringen av PostgreSQL 18 och mognaden av serverless databasteknologier har utvecklare nu tillgång till verktyg som tidigare var reserverade för företag i FAANG-skala. Oavsett om du bygger ett nischat B2B-verktyg eller en global företagsplattform, är valet av rätt databasdesignmönster det mest kritiska tekniska beslutet du kommer att fatta.
Arkitekturmönster för multi-tenant-databaser
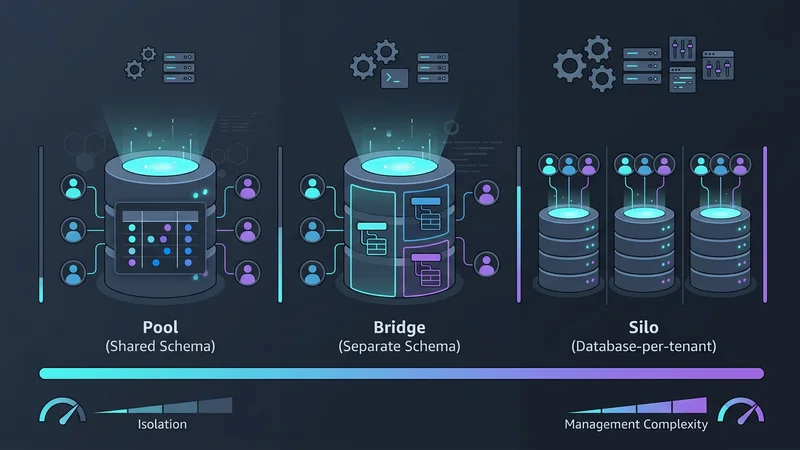
Att välja en multi-tenancy-modell innebär en avvägning mellan tre faktorer: Isolering, skalbarhet och kostnad. Under 2026 kategoriserar vi dessa i tre primära mönster: Pool, Bridge och Silo.
Mönster 1: Delad databas, delat schema (Pool-modellen)
"Pool"-modellen är den vanligaste arkitekturen för SaaS-applikationer med hög volym och låg kostnad. I detta mönster delar alla hyresgäster samma databas och samma tabeller. Data separeras logiskt med en tenant_id-kolumn i varje tabell.
Fördelar:
- Kostnadseffektivitet: Du betalar bara för en databasinstans.
- Enkel aggregering: Det är smidigt att köra analys på tvärs av alla kunder.
- Underhåll: Ett schema att migrera, en uppsättning index att hantera.
Nackdelar:
- Noisy Neighbor-effekten: En enda tung användare kan försämra prestandan för alla andra.
- Säkerhetsrisk: En bugg i din applikations
WHERE-klausul kan leda till dataläckage.
Mönster 2: Delad databas, separata scheman (Bridge-modellen)
"Bridge"-modellen används ofta inom HealthTech eller FinTech och utgör en medelväg. Varje hyresgäst får sitt eget schema (t.ex. tenant_a.orders, tenant_b.orders) inom en enda fysisk databasinstans.
Denna modell föredras under 2025 för miljöer med höga krav på efterlevnad, såsom HIPAA-kompatibla appar. Den ger logisk separation, vilket gör det svårare för data att läcka mellan hyresgäster, samtidigt som infrastrukturteamet fortfarande kan hantera ett enda databaskluster.
Mönster 3: Databas-per-hyresgäst (Silo-modellen)
Historiskt sett ansågs det vara en operativ mardröm att ge varje kund en egen databas. Framväxten av serverless-leverantörer som Neon och AWS Aurora Serverless v2 har dock revolutionerat detta. Dessa plattformar möjliggör "skala-till-noll"-funktioner (scale-to-zero), vilket innebär att en hyresgästs databas inte kostar något när den inte används.
Varför den vinner mark 2026:
- Noll läckage: Fysisk separation säkerställer att en hyresgäst inte kan komma åt en annans data.
- Anpassning: Du kan köra olika migreringar eller versioner för specifika företagskunder.
- Branching: Genom att använda "copy-on-write"-branching kan du onboarda nya hyresgäster omedelbart genom att klona en malldatabas.
Moderna innovationer & best practices (2025–2026)
Lanseringen av PostgreSQL 18 har i grunden förändrat hur vi implementerar dessa mönster. Två funktioner sticker ut: Inbyggd asynkron I/O (AIO) och inbyggt stöd för UUIDv7.
Skiftet till UUIDv7
I åratal debatterade utvecklare mellan sekventiella heltal (snabba men osäkra) och slumpmässiga UUIDv4 (säkra men långsamma för index). UUIDv7 är standarden för 2026 eftersom den är tidsordnad. Detta förhindrar den fragmentering av B-tree-index som är vanlig med slumpmässiga UUID:er, vilket håller dina inserts snabba även när din SaaS växer till miljarder rader.
Vektorisolering i AI-native SaaS
I och med framväxten av Retrieval-Augmented Generation (RAG) lagrar SaaS-databaser nu vektor-embeddings. "Vektorisoleringsmönstret" innebär att man använder Row-Level Security (RLS) på vektorkolumner för att säkerställa att en AI-agent endast hämtar kontext som är relevant för den specifika hyresgästen, vilket förhindrar "AI-hallucinationer" som involverar andra kunders data.
Strategier för dataisolering och identifiering av hyresgäster
Isolering är den "heliga graalen" inom SaaS. Under 2026 har branschen standardiserat två primära metoder för att säkerställa att ingen kund någonsin ser någon annans data.
Row-Level Security (RLS): Guldstandarden
Om du använder "Pool"-modellen är PostgreSQL:s Row-Level Security obligatoriskt. Istället för att manuellt lägga till tenant_id i varje fråga, definierar du en policy på databasnivå.
-- Aktivera RLS på tabellen
ALTER TABLE orders ENABLE ROW LEVEL SECURITY;
-- Skapa en policy som begränsar åtkomst baserat på en sessionsvariabel
CREATE POLICY tenant_isolation_policy ON orders
USING (tenant_id = current_setting('app.current_tenant')::uuid);Identifiering av hyresgäster via middleware
För att RLS ska fungera måste din applikation "berätta" för databasen vilken hyresgäst som är aktiv för tillfället. I en modern TypeScript-stack som använder Drizzle ORM eller Prisma hanteras detta i request-middleware.
// middleware/tenant-resolver.ts
import { NextFunction, Request, Response } from 'express';
import { db } from '../db';
export async function tenantMiddleware(req: Request, res: Response, next: NextFunction) {
const tenantId = req.auth.claims.tenant_id; // Extraherat från JWT
if (!tenantId) {
return res.status(401).send('Unauthorized');
}
// Använd en transaktion för att ställa in den lokala variabeln för denna anslutning
await db.transaction(async (tx) => {
await tx.execute(sql`SET LOCAL app.current_tenant = ${tenantId}`);
// Lagra transaktionsobjektet i requesten för användning i controllers
req.tenantDb = tx;
next();
});
}Varning: Använd alltid SET LOCAL inom en transaktion. Om du använder SET globalt på en poolad anslutning kan tenant_id "fastna" på anslutningen och läcka till nästa användare – ett fenomen som kallas Pool-kontaminering.
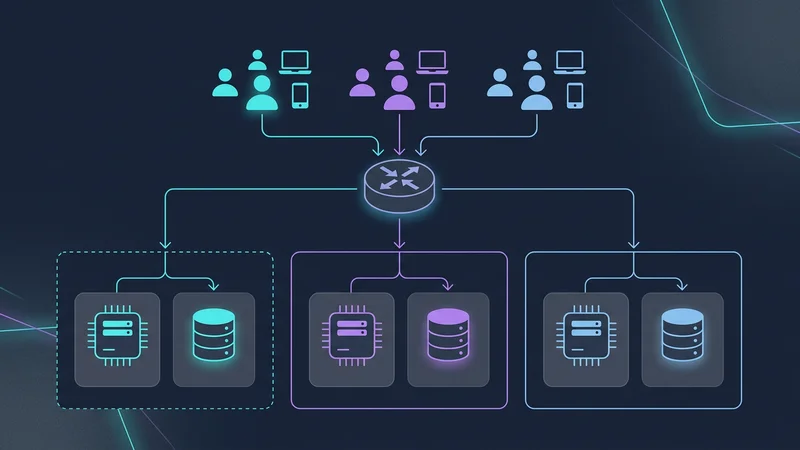
Skalningsutmaningar och Noisy Neighbor-problemet
När din SaaS skalar kommer du förr eller senare att stöta på en "Noisy Neighbor" – en enskild hyresgäst vars användning spikar så högt att den svälter ut andra hyresgäster på resurser (CPU, minne, I/O).
Cellbaserad arkitektur
För att mildra detta använder SaaS-applikationer i extrem skala (som Slack och Salesforce) Cellbaserad arkitektur. Istället för en gigantisk databas för 1 000 000 hyresgäster skapar du "celler". Varje cell är en fristående enhet (t.ex. ett databaskluster + beräkningskraft) som är värd för 50 000 hyresgäster.
- Skaderadie (Blast Radius): Om Cell A går ner påverkas endast 5 % av dina kunder.
- Global expansion: Du kan placera Cell B i EU och Cell C i USA för att uppfylla lagar om datalagring.
Distribuerad SQL för global SaaS
För applikationer som kräver en enda logisk global databas är distribuerade SQL-motorer som CockroachDB v25.4 det föredragna valet. De låter dig "låsa" specifika rader till geografiska regioner med hjälp av en regional_by_row-strategi, vilket säkerställer låg latens för användare samtidigt som global konsistens bibehålls.
Best practices för schemamigrering och underhåll
Att hantera migreringar för 10 000 separata hyresgästscheman är en omöjlig manuell uppgift. Automatisering via Infrastructure-as-Code (IaC) är den enda vägen framåt.
Automatisering av multi-tenant-migreringar
Moderna verktyg som drizzle-multitenant eller anpassade Terraform-providers låter dig behandla dina databasscheman som kod. När du uppdaterar ditt "mallschema" itererar CI/CD-pipelinen genom alla hyresgästdatabaser och applicerar ändringarna.
# Exempel: Köra migreringar över alla hyresgästscheman
npx drizzle-kit push:pg --config=./drizzle.config.ts --all-tenantsViktiga fallgropar att undvika:
- Slumpmässiga UUID:er: Som nämnts, undvik UUIDv4 för primärnycklar. Använd UUIDv7.
- Anslutningsutmattning: Att skala till 5 000 hyresgäster med separata anslutningar kommer att krascha din databas. Använd en tenant-aware anslutningspoolare som Supabase Supavisor eller PgBouncer.
- Saknade index på tenant-kolumner: I ett delat schema måste varje enskilt index inkludera
tenant_idsom den första eller andra kolumnen för att säkerställa att frågeoptimeraren kan filtrera data effektivt.
Vanliga frågor (FAQ)
Vad är skillnaden mellan silo-, bridge- och pool-databasmodeller?
Silo-modellen ger varje hyresgäst en dedikerad databasinstans, vilket ger maximal isolering men högre administrationskostnader. Bridge-modellen använder en delad databasinstans med separata scheman för varje hyresgäst, vilket balanserar isolering och kostnad. Pool-modellen använder ett delat schema där all hyresgästdata ligger i samma tabeller, separerade med ett tenant-ID, vilket ger högst kostnadseffektivitet men störst risk.
Hur säkerställer man dataisolering i en delad multi-tenant-databas?
Dataisolering säkerställs främst genom Row-Level Security (RLS) på databasnivå, vilket begränsar åtkomst baserat på användarens sessionskontext. Dessutom måste middleware på applikationsnivå strikt genomdriva identifiering av hyresgäster genom att injicera rätt tenant_id i varje fråga eller sessionsvariabel. Att använda tidsordnade identifierare som UUIDv7 hjälper också till att bibehålla prestanda och ordning i delade index.
Vilken databasarkitektur är bäst för en SaaS-applikation som skalar?
För SaaS i tidiga skeden är Pool-modellen med RLS vanligtvis bäst på grund av dess låga kostnad och enkelhet. När du skalar upp till företagskunder föredras en hybrid- eller cellbaserad arkitektur, där de flesta användare stannar i en delad pool medan värdefulla företagskunder migreras till dedikerade silon för bättre prestanda och efterlevnad.
Hur hanterar man schemamigreringar för tusentals hyresgäster?
Schemamigreringar bör hanteras med Infrastructure-as-Code (IaC) och automatiserade migreringsverktyg som kan utföra ändringar parallellt över alla scheman. Verktyg som Drizzle ORM eller specialiserade CI/CD-skript används för att säkerställa att migreringar är idempotenta och att fel i en hyresgästs migrering inte stoppar hela distributionsprocessen.
Kan multi-tenancy påverka databasens prestanda och latens?
Ja, multi-tenancy kan leda till Noisy Neighbor-problemet, där en hyresgästs tunga resursanvändning förlångsammare frågor för andra. Dessutom kan overhead för att hantera tusentals hyresgästkontexter öka latensen avsevärt och riskera anslutningsutmattning om man inte har korrekt indexering på tenant_id och använder anslutningspoolare.
Slutsats
Databasdesign för SaaS under 2025–2026 handlar inte längre bara om att välja mellan SQL och NoSQL. Det handlar om att välja en strategi som ligger i linje med dina affärsmål.
Om du bygger en konsumentapp med hög volym erbjuder Shared Schema (Pool)-modellen med PostgreSQL 18 och RLS bäst prestanda och kostnad. Om du siktar på företagsmarknaden ger Serverless Silo-modellen den isolering och efterlevnad som dina kunder kräver, utan den historiska bördan av att hantera tusentals servrar.
Genom att standardisera på UUIDv7, implementera cellbaserade arkitekturer för skalning och utnyttja automatiserade migreringsverktyg, kan du bygga en SaaS-backend som inte bara är robust idag utan redo för nästa decenniums krav.